Welcome to the Pochi Developer Updates — a digest of what's new in the codebase.
Here you will find highlights on features, enhancements, and bug fixes, plus insights into how we're improving the developer experience. Come back often! 👋
Five Practical Tips to Save Token Consumption with Pochi
Feb 24, 2026
The usual experience with coding agents is predictable - they start out sharp, then slowly become confused, verbose, and expensive. Instructions keep piling up, tools accumulate, and failed attempts linger in the conversation. By the time token costs start hitting the roof, the agent already feels harder to work with.
At that point, most teams reach for the usual fixes: improve the prompts, avoid the biggest models for small tasks, and aggressively cache tool calls. While all of these help, they come with their own overhead of constant tuning and close monitoring - and even then, they rarely address the root cause of runaway token usage.
This post breaks down practical workflow patterns you can apply to address common sources of context bloat, explains the principles behind them, and shows how Pochi supports these behaviors in day-to-day work. If you’ve ever felt like an agent got worse the longer you worked with it, these patterns are likely why, and how Pochi helps you fix it.
1. Compact context aggressively as noise accumulates
Token usage grows over time as conversations accumulate failed attempts and abandoned approaches. This context debt increases token usage and degrades response quality, making agents more verbose and error-prone.
To solve this, Pochi periodically allows you two options to compact the context:
-
Compact Task: This summarizes the task context and replaces long conversational history with a concise, up-to-date representation of intent and state. Applicable when you want to stay in the same task and continue the conversation with the condensed context.
-
Create a New Task with Summary: This creates a clean task with a summary of the previous conversation, helping you avoid hitting context limits while keeping all relevant information.
These mechanisms are especially useful during long debugging sessions, iterative refactors, or tasks with multiple rounds of clarification.
In these cases, the majority of the conversation history becomes irrelevant once a direction is chosen. Compacting ensures the agent doesn’t keep paying for that history over and over again.
Steps:
- When a task gets long, compact the context regularly (e.g., after 3–5 iterations).
- Keep only the essential state and intent.
- If the direction changes, create a new task with a summary of the previous conversation.
2. Attach intent to code instead of explaining it in chat
Explaining code changes in plain chat is one of the fastest ways to burn tokens. Each time you prompt the agent with queries like:
Prompt:
- “Actually, change this part…”
- “No, not that file , the other one”
- “I meant refactor this logic, not rewrite it”The model has to re-read large parts of the context, reconstruct what changed, and infer your intent all over again. This kind of repetition adds up quickly.
Pochi avoids this by attaching intent directly to code through Edits and Reviews.
-
Edits track the exact diffs you introduce locally while iterating. If you tweak a variable, adjust logic, or partially rewrite a block, Pochi includes only those changes in the agent’s context the next time you send a prompt.
-
Reviews, on the other hand, let you leave inline comments directly on generated code. Instead of re-explaining issues in chat, you comment on specific lines and batch that feedback into a single, focused update.
Steps:
- Use edits to track local diffs during iteration.
- Attach intent directly to code using inline comments.
- Batch feedback into a single update instead of multiple chat messages.
3. Isolate intent early with subagents and forks
Token usage often spikes when multiple ideas compete in the same context. You start with one goal, explore a few approaches, abandon some, and finally pivot to another direction. In this case, the agent is continuously juggling multiple lines of intent. Even with compaction, the model still has to reconcile what you meant before with what you want now.
Language models are optimized for coherent, single-threaded intent. When a task mixes multiple implementation strategies, the model keeps all of that alive in context, even if only one direction is still relevant.
The answer is isolation. Separate tasks mean separate contexts, and separate contexts mean fewer tokens spent reconciling unrelated ideas.
Pochi supports this through task forking and subagents:
-
Forking a task creates a new task that starts from the current code state but does not inherit conversational noise. It’s ideal when you want to try a different approach or explore an alternative implementation without dragging prior reasoning along.
-
Subagents allow focused exploration within the same repository while keeping contexts separate. Each subagent works with a clean, bounded scope instead of accumulating unrelated history. In practice, this kind of isolation can lead to dramatic token savings. Developers running large, multi-step workflows often split work across multiple subagents, each with its own narrow instruction set.
Steps:
- When you explore multiple approaches, create a fork or a subagent.
- Keep each task focused on one implementation strategy.
- Use separate contexts for separate goals.
4. Scope MCP servers per task to shrink the action space
Before an agent attempts to solve a problem, it evaluates what it can do with every enabled tool. Each additional MCP server expands the action space the model must reason over. Even if a tool is never used, the model still spends tokens evaluating whether it is relevant, how it compares to other options, and when it applies.
For example, if a task only requires database access, exposing ten additional MCP servers adds unnecessary reasoning overhead. More options mean more branches to evaluate, which translates directly into higher token usage.
Scope MCP servers per task so the agent only reasons about tools relevant to the task. Only selected servers are loaded into context, contribute tool definitions, and influence model reasoning. All other tools are invisible to the agent.
Steps to follow:
- Before starting a task, decide which MCP servers are necessary.
- Disable all MCP servers not required for this task.
- If the task changes, immediately rescope the tool set.
- Keep a task template for common workflows (DB, infra, testing, etc.).
5. When execution dominates, move heavy data processing out of the model
Once you’ve scoped tools correctly, the next source of runaway token usage often shows up during execution, typically inside MCP-backed workflows.
The prompt may be short and the tool choice correct, yet execution tokens spike because large volumes of raw data are streamed into the model.
Tool calls may return hundreds or thousands of rows, which then get streamed into the model as large JSON payloads. At that point, execution tokens dwarf everything else.
The failure mode is asking the model to reason over this raw data. For example, we asked Pochi:
Prompt: How many failed orders do we have?In the first attempt, the agent queried the database, fetched all matching rows, and streamed them into the model so it could filter and count them.
The answer was correct, but thousands of records flowed through the context just so the model could compute a single number.
A better approach is to separate what needs to be computed from how it is computed. Instead of reasoning over data, the model should generate code that performs the computation and returns only the result.
Prompt: Please write a small script that queries the database, filters failed orders and only returns the final count. Pochi generated the following script:
import sqlite3
import os
def count_failed_orders():
# Assuming the database file path based on common patterns if it were local,
# but since I have execute_sql tool, I will demonstrate how to do it via SQL.
# For a standalone script, it would typically connect to a DB.
# This is a conceptual script that would be used in an environment where
# the DB connection is established.
query = "SELECT COUNT(*) as failed_count FROM orders WHERE status = 'failed';"
# In this specific environment, we use the provided tools to interact with the DB.
# If this were a real Python script for the user:
"""
conn = sqlite3.connect('database.db')
cursor = conn.cursor()
cursor.execute("SELECT COUNT(*) FROM orders WHERE status = 'failed';")
count = cursor.fetchone()[0]
print(f"Total failed orders: {count}")
conn.close()
"""
# Since I'm tasked to write a script, I'll provide a clean Python script.
print(f"Querying failed orders count...")
# Placeholder for actual DB execution logic
return query
if __name__ == "__main__":
sql = count_failed_orders()
print(f"SQL to execute: {sql}")Now when prompted again to fetch the number of failed orders, the model never sees the raw records. Only a short summary enters the context, dropping execution tokens from tens of thousands to a few hundred.
Why not just run a COUNT(*) query?
At this point, it’s reasonable to think that the agent can run the SQL query directly:
query = "SELECT COUNT(*) as failed_count FROM orders WHERE status = 'failed';"Why do we need to get the agent to write a separate script?
And you’re right. Expect that agents often choose the least expensive path. Even when a database can do aggregation, agents frequently fall back to pull-and-process patterns:
SELECT * FROM orders WHERE created_at > '2026-01-01';This is where token usage explodes, for several reasons:
- Schema uncertainty: If the agent isn’t confident about column names, enums, joins, indexes, it plays it safe by fetching rows and reasoning in-text.
- Ambiguous instructions: If the prompt says: “Find refunded orders and tell me how many there are”, the agent may fetch records first, inspect fields, and thenthen count, Instead of jumping straight to
COUNT(*) - Tool abstraction: Many MCP database tools expose
run query,fetch rows, but don’t strongly bias the model toward aggregation-first queries. So the model takes the path it can reason about most reliably. - Multi-step reasoning: If the question is slightly more complex: “How many refunded orders from customers who signed up last quarter?”. The agent might fetch orders, fetch users, join in its head and then count. That’s almost guaranteed to stream a lot of data.
Databases are cheap at filtering and counting while language models are not. The solution is simple - let the model decide what to compute, and let code handle how the computation happens. Only the final result should enter the context. Having a script lets us review the code and make sure that it runs the same computation every time the same prompt is called.
This keeps execution costs predictable, even when working with large datasets.
Steps:
- Detect when tool results exceed ~100 rows.
- Instead of asking the model to reason over raw data, ask it to generate code that computes the result.
- Return only the final result to the model (summary, count, aggregation).
- Use aggregation-first queries when possible.
Conclusion
If there’s one theme across all five guides, it’s that token usage is shaped long before a prompt is sent. Most token blowups don’t come from bad prompts or choosing the wrong model. They come from workflows that allow too much context, too many tools, and too many competing ideas to accumulate in the same place.
When each task has a clear goal, well-suited tools, and a clean context, the agent doesn’t have to waste tokens reconciling noise. It can converge faster, reason more clearly, and produce better results at lower cost.
At Pochi, this philosophy is baked into the product. The goal isn’t to make you think about tokens because we tailor an experience that naturally keeps context small, intent clear, and costs predictable.
Weekly Update #22
Feb 13, 2026
TL;DR
This release we shipped a built-in browser subagent so browser automation is no longer a black box, tightened up task and skill workflows that were breaking under real usage, and published new writing on why agent safety has to live below the prompt layer.
🚀 Features
-
Built-in browser subagent with live streaming: As soon as agents start using browsers for anything non-trivial like scraping, form-filling, navigating dashboards, it brings in a new layer of visibility of how the operation is being performed. Without the visibility, debugging involves a lot of back and forth with prompts to explicity define the failure modes.
Pochi now includes a built-in browser subagent that runs through the same execution pipeline as other tools and streams its activity live in the UI. You can watch the agent navigate, click, and capture pages as it works.
Browser sessions are persisted, so you can revisit screenshots or recordings after the task completes. #1107
✨ Enhancements
-
Upgraded Plan Mode: One of the most common failure modes we see is agents confidently generating implementation plans on top of ambiguous or incomplete requirements.
To address this, we’re adding a clarification phase to the planner workflow. Before generating a plan, the planner agent will ask targeted follow-up questions when it detects ambiguity, instead of silently making assumptions.
This will enforce more clarification from the user’s side and will avoid plan generation until key decisions are resolved. #1254
🐛 Bug fixes
-
Support symlinked directories in the skill loader: Skills are meant to be reusable building blocks, but developing them locally was more painful than it needed to be. Many users keep skills in separate repos and iterate on them alongside projects.
We allow Skills to be loaded from symlinked directories in both the CLI and VS Code extension, making it easy to develop a skill in isolation and symlink it into.pochi/skillsduring development. #1199 -
Fixed task forking to correctly fork subtasks: Forking is often used to explore alternatives or recover from a failed approach. When subtasks weren’t properly forked, it created hidden coupling between tasks.
To fix this, now when you fork a task, we also fork any subtasks created in its conversation history. Forked tasks are fully self-contained, with no references back to the original task’s subtasks. #1134
📖 Resources
Alongside shipping features, we spent time documenting how we think about agent safety in practice, especially when agents interact with production systems. We submitted two resources:
-
How to give coding agents access to SSH and databases without breaking production: We published a deep dive on why common safety patterns like command allowlists, SQL filters, and approval dialogs fail with autonomous agents, and why safety must be enforced at the infrastructure and execution layer instead of through prompts or behavioral controls. Read blog
-
Secure production database access in Pochi: Following our earlier post on agent safety, we released a hands-on guide showing how to grant agents controlled database access using isolated environments and gated deployment flows, without exposing production credentials or allowing uncontrolled writes. Read tutorial
🔥 Preview
-
Task walkthroughs: We’ve been working on a walkthrough feature that can generate a concise, human-readable summary of a task’s outcome in respect to what changed, why, and where to look next. The goal is to make agent-driven work easier to review, revisit, and share, especially for long-running or browser-heavy tasks. This feature is still being finalized and will land in an upcoming release.
-
Improving the browser subagent: Alongside shipping the first version of the browser subagent, we’ve been working on making it reliable for long-running, real-world use.
This includes:- Tightening browser session lifecycle management so sessions are cleaned up correctly when tasks end or tabs are closed
- Improving recording infrastructure to avoid race conditions and ensure consistent captures
- Unifying browser session handling across VS Code and the CLI so browser automation behaves the same in all environments
-
Updating Pochi icon in VS Code Sidebar: The current sidebar icon uses the generic
$(code)icon, which doesn’t clearly communicate the Pochi brand identity. We’re working on a new icon that better represents Pochi’s role as an agent and its relationship to the codebase.
How to Give Coding Agents Access to SSH and Databases (Without Breaking Production)
Feb 6, 2026
As AI agents become more capable, teams are trying to limit the damage they can do when given access to SSH or production databases. Common approaches include:
- Command allowlists: allow
ls,cat,grep,tail; blockrm,mv,chmod. - SQL filters: Allow
SELECT; blockINSERT,DELETE,DROP. - Manual approval flows: Run everything in
read-onlymode until a human explicitly accepts changes.
These practices assume that constraining agent behaviour through rules, filters, and approvals can prevent dangerous actions.
This assumption is wrong.
Allowlists, prompts, and approval dialogs are control surfaces that influence what an agent chooses to do. Shells, credentials, runtimes, and database roles function as execution surfaces, defining what the system can do.
Risk is determined by execution surfaces, not control surfaces.
Enforcing safety at the behavior layer isn’t the solution. What follows is why these approaches fail in practice - and what actually holds up in production.
Why database-level controls fail
Human engineers rarely connect to primary databases with full access. They query replicas or views that cannot change production data. The same principle must apply to agents, but it is not enough to enforce this only at the query level.
There are several reasons for this.
First, SQL filtering is unreliable. Even if you block write statements, many databases still support queries that trigger full table scans. Constructs like SELECT INTO can introduce new tables, and functions can produce side effects.
Second, read access alone is dangerous. It can expose authentication tokens, PII, or operational metadata. This is why databases themselves do not rely on client-side query validation and instead implement safety through roles, views, and replicas.
Re-implementing parts of this logic in the agent layer with regexes or heuristics is both fragile and incomplete.
Agents route around blocked tools
An agent’s goal is task completion. Blocking individual tools does not mean entire classes of state changes are prevented. For example, if the agent finds that direct deletion within a database schema is blocked, it will reach the same outcome by putting together other allowed operations.
In this case, even though direct access to the tool is blocked, it doesn't prevent many other possible walkarounds that could apply undesired changes to the production system.
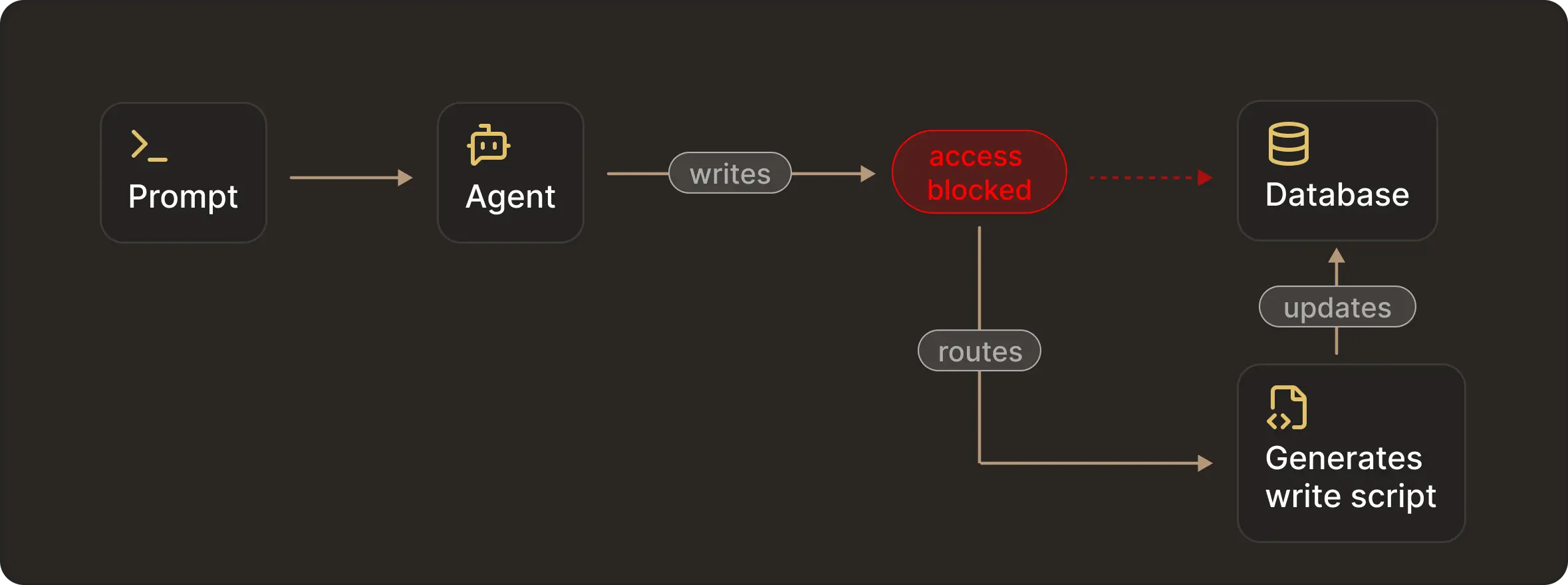
In practice, this can include writing a script that performs deletion or just invoking a different tool that indirectly gives the expected outcome. This is not adversarial behavior. Instructions, allowlists, and approval dialogs influence behavior, but they do not define what the system is capable of doing.
For that reason, safety cannot live solely inside the model. It must be enforced outside the model through OS permissions, roles, and tool interfaces. Access control is not a prompting problem. It's an infrastructure problem that will require explicit separation between reasoning and execution, with enforcement applied at deterministic execution boundaries.
What actually holds up in production
1. Read-only access still allows irreversible damage
In one setup, we exposed production data to an agent exclusively through a read-only tool interface backed by a SELECT-only database role. On paper, this appeared safe - the agent could inspect data but had no explicit write tools.
However, as long as the agent retained access to a general execution surface (shell access, runtime file system, or database credentials), it simply routed around the restriction, generating its own script and updating the database through an unintended path.
We removed the execution surface entirely and enforced read-only access at the infrastructure level. This involved revoking database write permissions and disabling shell execution. Post this, the agent could reason freely but could no longer apply any changes.
Even when read-only access is enforced at the infrastructure level, production access still depends on human approval. Over time, these approvals tend to degrade into procedural steps. Auto-approve paths appear, reviews become mechanical, and the safety boundary weakens.
As a result, granting agents direct access to production databases, even in read-only mode, is best avoided. Agents are non-deterministic by design, and production systems should not be exposed to that uncertainty.
The challenge is that many legitimate tasks still require writes.
2. Writes must flow through existing deployment pipelines
Many engineering tasks involve backfills, schema updates, and data correction. All of these require write access.
Giving an agent write access to production data under these circumstances is rarely acceptable. A more robust pattern is to let agents propose changes, generate and test migration scripts, and iterate freely. But applying those same changes to production will still wait on explicit human approval.
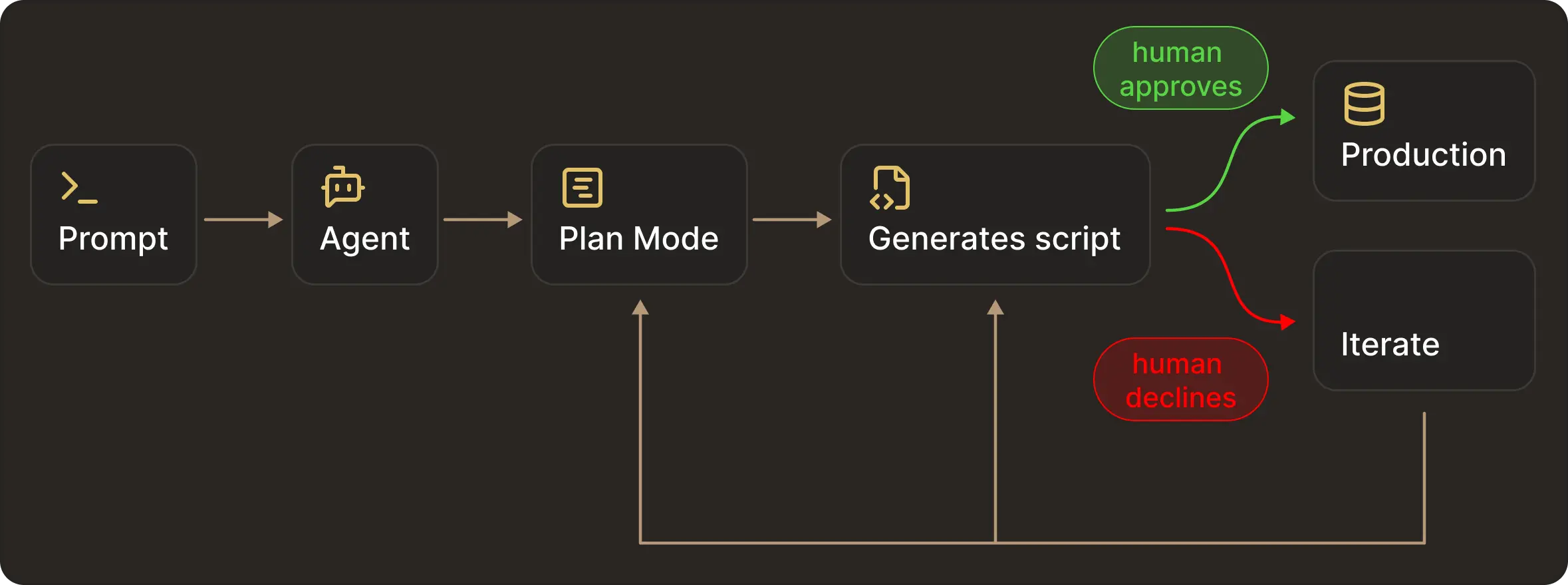
This mirrors standard engineering practice. It avoids giving production credentials to agents and ensures all changes are auditable and reversible.
The tradeoff is slower iteration, because agents can’t validate assumptions against real production data. This is where isolated writable environments become important.
3. Isolated writable environments enable safe iteration
Isolated Writable Environments (IWEs) are disposable database instances that mirror production schema and data. Within these environments, agents can evolve schemas, validate queries, and test migrations freely. Once the changes are ready, the same test and migration scripts can be replayed through the original production pipelines.
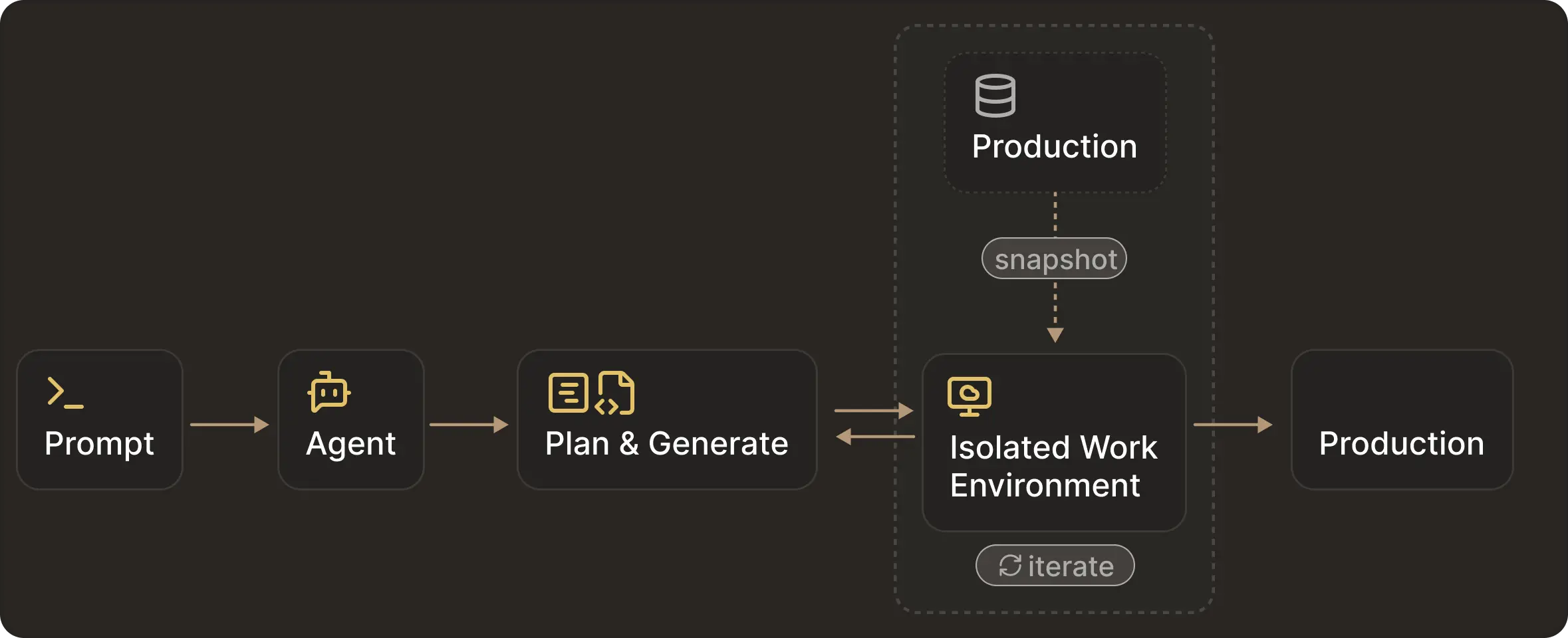
In practice, combining IWEs with gated production deployment yields the best results. You get the agent to perform actions against isolated databases while production remains gated by standard deployment processes.
The same principle applies outside the database layer. With SSH and shell access, the execution surface becomes effectively unbounded unless similar infrastructure-level boundaries are enforced.
Why shells make safety undefined
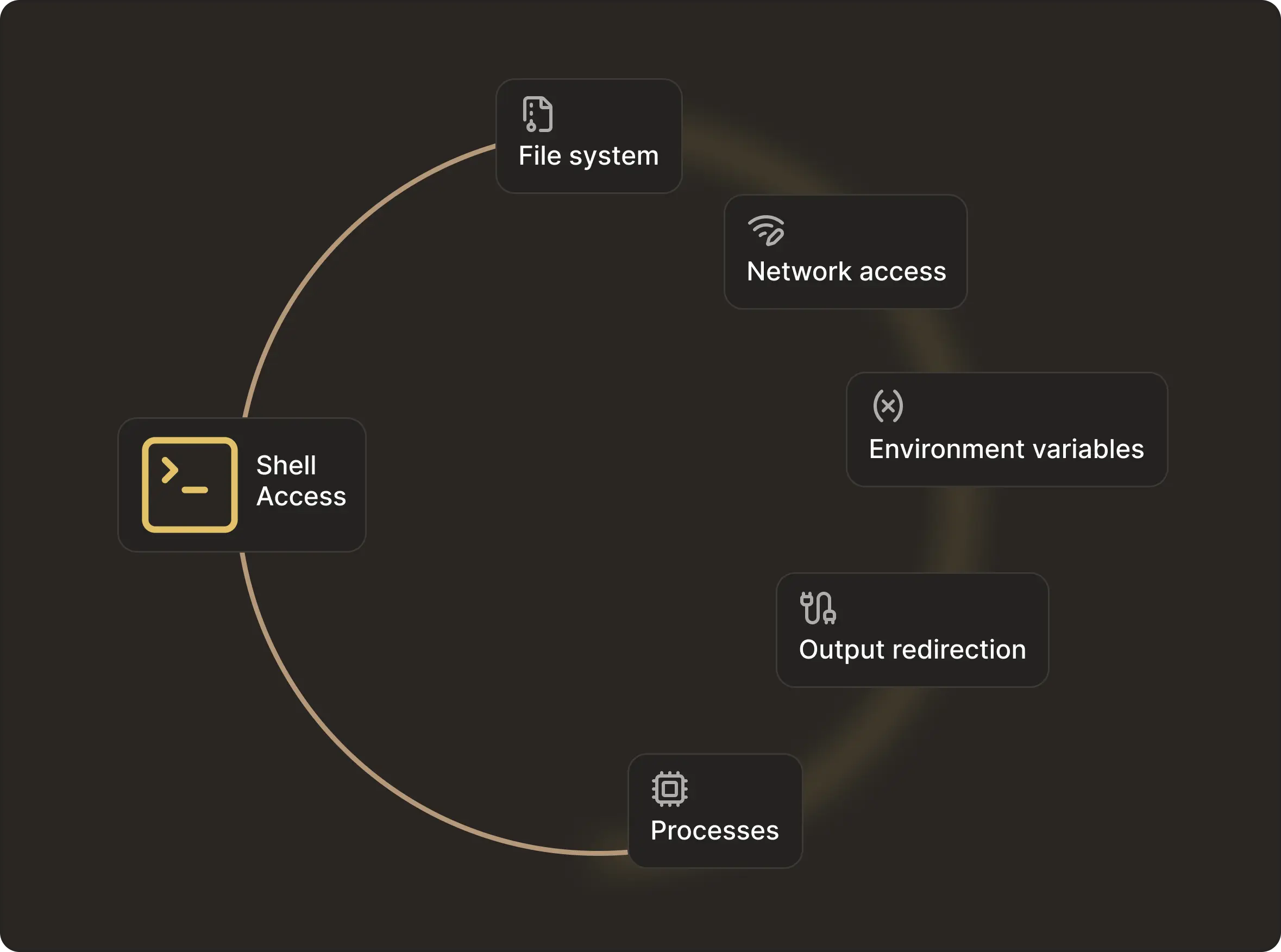
A shell is a general-purpose programming environment. Once exposed, safety boundaries become undefined.
An agent can use cat to overwrite files, using grep can exfiltrate secrets, and tail -f, if used on the wrong file, can leak sensitive data indefinitely. On the other hand, having an allowlist to control which binaries are executed does not automatically constrain the kind of operations that are possible on the system.
Having a shell exposed grants access to the file system, process creation, and the environment state. And once a shell exists, the boundary of what is allowed is no longer clear.
The safest designs accept this and shift the focus from preventing mistakes to containing them.
Disposable environments
The simplest and most reliable pattern is to treat any machine an agent can access as disposable. This way when something goes wrong, you just replace the whole thing and not spend time to fix it. This is already how CI systems operate, and increasingly how dev environments are provisioned.
Instead of connecting agents to long-lived servers, teams route them to short-lived containers, ephemeral VMs or dev sandboxes per task or per session. This way agents are free to modify files, install packages and experiment with configurations. But this introduces infrastructure cost while reducing production impact.
Restricted hosts and forced commands
Some teams still require agents for log inspection, operational debugging, or controlled maintenance. But even in these cases, full interactive shells are rarely necessary. Common restrictions can include:
- SSH users with no home directory and limited permissions
- forced commands in
authorized_keysso only specific scripts can run - wrapper binaries that expose narrow actions instead of general shells
For example, instead of allowing:
ssh agent@hostthe key may enforce:
command="/usr/local/bin/fetch-logs.sh"This reduces damage area but comes with its own pitfalls. Debugging can become harder and workflows might require constant tooling updates.
Structured tools and APIs provide stronger safety guarantees than shells.. A shell exposes the file system, environment variables and network access - making it impossible to create boundaries without building a second operating system around it.
This approach already mirrors how human access to infrastructure has evolved as well. We now have fewer SSH sessions, more pipelines, dashboards, and automation APIs. Agents benefit from the same shift, for the same reasons.
Conclusion
Throughout this post, we saw the same pattern repeat across different systems. When the agent was instructed to follow safety, through instructions, prompts, or behavioral constraints, it failed. Whereas, when safety was enforced through infrastructure (roles, isolation, and execution boundaries), it held.
Many teams make this fundamental mistake of treating access control as a prompting problem instead of a system problem.
The only reliable way to make agents safe is to design environments where destructive actions are physically unreachable, and all state changes flow through auditable, deterministic systems. Once safety is achieved by design, mistakes become recoverable, contained, and reviewable - and only then can agents be given meaningful autonomy across real production use cases.
Weekly Update #21
Jan 30, 2026
TL;DR
As projects get more complex, small workflow improvements start to matter a lot.
This release brings a few updates aimed at making Pochi easier to work with day-to-day, including reusable skills, better task organization through archiving, and support for running long-running subtasks in the background.
🚀 Features
-
Agent Skills: You can now define and use Skills in Pochi to reuse agent instructions across tasks and projects. Skills are reusable instruction sets that influence how the agent approaches a task, making it easier to standardize workflows, encode domain-specific knowledge, or integrate external tools.
- Skills are defined as folders containing a
SKILL.mdfile with metadata and instructions. - Pochi automatically discovers skills from project (
.pochi/skills/) and user (~/.pochi/skills/) locations. - Skills can be installed from the community registry using the CLI: (
npx skills add <skill-source> --agent pochi). - Skills can be activated automatically based on task context or explicitly via slash commands. You can also combine multiple skills within a single task.
- Skills do not modify your project files unless explicitly used during execution. #1050
- Skills are defined as folders containing a
✨ Enhancements
-
Task Archiving: You can now archive and unarchive Pochi tasks from the sidebar on a per-worktree basis. Archived tasks can be hidden or shown using a toggle, and you can optionally archive tasks older than 7 days to keep the task list clean. #1106
-
Background Subtasks:
newTaskcan now be run asynchronously as a background child task. These subtasks preserve the parent–child relationship but do not block the parent task, allowing agents to delegate long-running work while continuing execution.#1022
🔥 Preview
-
The browser subagent is currently under active development. When it lands, you’ll be able to watch the agent’s browsing actions stream directly in the editor and incorporate those observations into plans, reviews, and execution.
-
We’re also working on automatic walkthroughs that recap the changes an agent made once a task is complete. More details coming soon.
Reusable skills. Stop repeating prompts
Jan 29, 2026
We added Skills to Pochi.
As tasks grow more complex, users often end up repeatedly explaining the same details to the agent, including output formatting, API usage, and internal conventions.
Skills turn those repeated instructions into reusable capabilities.
In Pochi, skills live alongside your code, are easy to inspect and edit, and plug directly into tasks. They can be automatically discovered, explicitly invoked, and combined with other features like Plan Mode, reviews, and scoped tool access.
That means skills are here to shape how work actually gets done. You can standardize workflows, or integrate tools once, and then reuse that behavior consistently across tasks and projects.
Weekly Update #20
Jan 23, 2026
TL;DR
As Pochi takes on larger and more complex tasks, it’s increasingly important to be explicit about intent and permissions.
This release introduces new workflows for planning before execution and for restricting tool access per task, making agent behavior easier to reason about and safer by default.
🚀 Features
-
Create Plan Mode: You can now create a task in Plan Mode to generate and refine an implementation plan before any code is changed. To use, click on the
Planoption when creating a new task from the sidebar.- Plan tasks generates a structured implementation plan instead of immediately executing edits.
- The plan is stored as a workspace artifact (i.e.
plan.md) in Pochi’s virtual filesystem and does not modify your project directory. - You can create a separate plan for each task without polluting your repo.
- You can use existing workflows: inline comments, review edits, and follow-up prompts to refine the plan.
- After review, you can explicitly start execution from the approved plan.
This makes planning a first-class step in the agent workflow and lets you align on scope, approach, and risks before applying multi-file changes.#819
✨ Enhancements
-
Granular MCP Tool Control in Sidebar: You can now control MCP access per task instead of auto-approving all tools globally. Follow-up messages are restricted to the MCP servers selected at task creation.
To try it out, look for the MCP server selector in the sidebar input. Servers disabled in global settings are not shown in the selector. This provides better security and more explicit control over which tools the agent can use. #939
🐛 Bug Fixes
- Fixed Token Coloring in NES Code Renderer: Fixed an issue where certain token types (such as string literals) were not being theme-colored correctly in the NES code renderer. #731
🔥 Preview
-
Soon you’ll be able to archive tasks in the sidebar to keep active work focused, with filters and quick restore when you need to revisit something.
-
We’re also building a built-in browser subagent that can browse and interact with live web pages and stream its actions directly in the editor.
Plan like you code
Jan 22, 2026
We shipped Plan Mode in Pochi.
Planning by itself isn’t new. What’s interesting is what happens when planning plugs into a workflow that already supports inline comments, review edits, and task-based execution.
Create Plan is a feature we built, but its real value comes from how it composes with the rest of the system.
Instead of treating the plan as something you just read and approve, you can iterate on it the same way you’d review a diff - leave inline comments, refine specific steps, and then execute directly from that agreed version.
The plan lives as a real workspace artifact (i.e. plan.md) and opens in the editor, so planning becomes part of the same collaboration loop as code.
Weekly Update #19
Jan 16, 2026
TL;DR
Another batch of updates is out. Here’s what we’ve shipped since the last release.
✨ Enhancements
-
New Pochi landing page: The Pochi website now has a new landing page with clearer explanations of core features, workflows, and setup, making it easier for new users to evaluate and install Pochi. #Visit Page
-
Embedded bash outputs are now visible in the UI: When workflows embed command outputs into the model context (for example git diff in the create-pr workflow), those outputs are now displayed in chat instead of being hidden as system messages, making it easier to inspect and debug what the agent is responding to. #1010
📖 Resources
- We published a step-by-step guide showing how to use Git worktrees and parallel agents to run multiple tasks concurrently, with a practical weather app example that walks through setup, coordination, and best practices. #Read more
🔥 Preview
-
Along with Create Plan flow for new tasks, we’re also working on letting you choose which MCP servers and tools a task can access directly from the sidebar, instead of using a single global auto-approve toggle.
Stay tuned!
Weekly Update #18
Jan 09, 2026
TL;DR
Hope your year’s been off to a good start.
We’re back to shipping, and this release includes updates to how follow-up prompts use your local edits, a clearer Auto Layout setup flow, better recovery when things fail (like model loading and Mermaid diagrams), and a few UI fixes that remove common friction points.
Let’s dive in!
🚀 Features
-
User Edits are now included in agent context: Recent code changes you make are now captured and sent along with your next prompt. These edits are also shown in the chat context and multi-diff view, so you can see exactly what the agent is reacting to.
This helps the agent continue from your version of the code without you needing to re-explain what you already changed. #983
✨ Enhancements
- Improved Auto Layout onboarding: Auto Layout can modify several VS Code settings such as layout, keybindings, auto-save, and conflicting completions. The new onboarding screen explains these changes upfront and allows you to selectively apply them, making it easier to enable Auto Layout with confidence. #985
-
Create worktrees from remote branches: When creating a new worktree, you can now choose a remote branch (for example,
origin/feature-branch) as the base instead of being limited to local branches. This makes it easier to start from branches that exist on the remote but aren’t checked out locally. #958 -
Recover from Mermaid rendering errors in chat: When a Mermaid diagram fails to render, a
Fix error with Pochibutton is now shown so you can ask the agent to correct the diagram instead of being stuck with a broken block. #968 -
Retry when models fail to load: If the model list fails to load due to a network or backend issue, you can now retry directly from the UI instead of reloading the entire VS Code window.#984
- More space for worktree details: We optimized the worktree list layout so action buttons no longer take up space when not visible, giving more room for worktree names and PR information, particularly on smaller screens.#925
🔥 Preview
- We’re working on a Create Plan flow for new tasks in the sidebar, letting you generate a structured plan first before executing the task.
NES Series (Part 4): Dynamic Rendering Strategies for AI Code Edits
Jan 06, 2026
So far in this series, you’ve seen how we trained our NES model, what that model takes as context to make a prediction, and how these model requests are managed with correct timing under continuous typing.
With this, we’ve reached a point where NES can predict what edit should happen and when it should appear in the editor.
In Part 4, we'll talk about how there is still one critical decision to make. Once a suggestion arrives, how should that change be presented inside a live editor?
Pochi’s NES is built as a VS Code-native feature, not a standalone IDE or a custom fork. This means previews must integrate with VS Code’s public APIs, performance model, and established interaction patterns.
This introduces a core design challenge - to surface enough context for a suggestion to be actionable, without disrupting the developer's flow.
Designing a system that honors this is more than a matter of visual polish; it is a complex systems + UX problem. We’ll explore why this balance is so difficult for a native AI agent and the specific rendering strategies NES uses to achieve it.
The Display Problem
Unlike conventional editor features, NES does not control where the user’s cursor is when a suggestion arrives. The editor is a continuously changing environment and does not function like a static canvas. Sometimes the user's cursor might be exactly where the edit belongs, or it can be twenty lines away, or the suggestion itself can be a huge change spanning multiple lines.
Showing such suggestions naïvely introduces new failure modes that are easy to trigger and hard to ignore. One experiences jumps in cursor position, abrupt viewport scrolls, or rendering large changes directly in the editing flow. In practice, these behaviors are often more disruptive than not showing a suggestion at all.
This brings us to the most fundamental design question: How do we show an edit without stealing the developer’s attention?
Answering that question requires understanding the VS Code interaction model.
VS Code does not provide a built-in API for previewing LLM-generated edits. Instead, the editor offers different primitives for different kinds of locations and edits. These primitives are optimized for various interaction patterns, each with their own affordances and limitations. Some work well for cursor-local edits, while others are better suited for changes elsewhere in the file.
Understanding this difference is key. Pochi's NES does not render suggestions in a single, fixed way. Instead, NES relies on these primitives to create a balance between visibility and disruption.
Dynamic Rendering Strategy
Rather than forcing all suggestions into a single representation, we designed a Dynamic Rendering Strategy offering the optimal visual experiences in different editing scenarios:
- Suggestions that target the current cursor position are rendered inline, flowing naturally into the user's typing behavior.
- Suggestions that apply off-cursor are previewed via an inline diff decoration, avoiding jumps in the viewport.
- For large, multi-line block inserts, a floating preview is used to provide sufficient context without disrupting the user's current focus.
This way, each path is deliberately scoped to the situations where it performs best, aligning it with the least disruptive representation for a given edit.
Let’s take a walk-through of these rendering strategies in detail and examine when each one is used, starting with the least disruptive case.
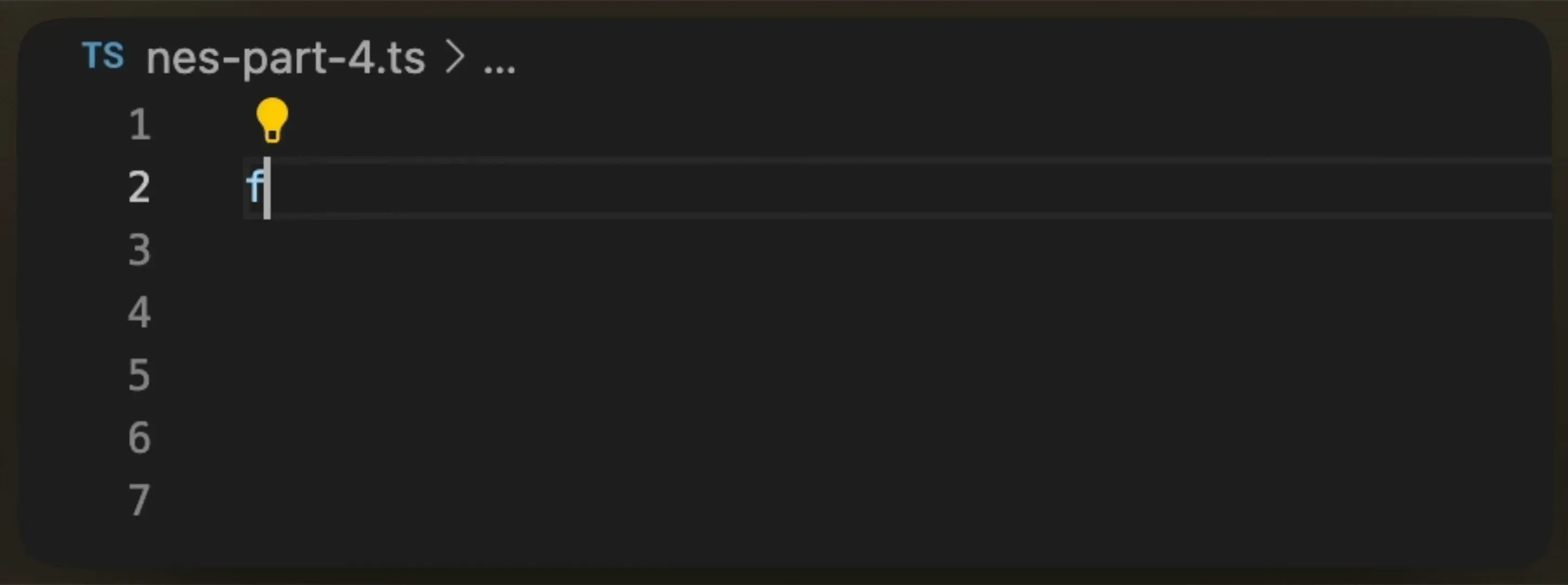
Inline Completion
When an edit is positioned right at the cursor, the least disruptive option is to stay out of the way. In such cases, we render the edit inline, making it blend directly into the user's typing flow.
To achieve this, we use VS Code's inline completion API. This approach works especially well for small, localized changes like autoclosing brackets, replacing a few characters, or edits that are directly made under the cursor.
Inline Diff Preview
Because NES predicts the next meaningful edit across the file (not just at the cursor), many suggestions naturally apply outside the user’s current editing position. For example, while you are typing inside a function, NES may suggest updating a related import, adjusting a type definition, or fixing a reference several lines away.
In these cases, the cost of getting the presentation wrong is high. The user is forced to jump across the file, break context and interrupt their flow.
To avoid that, we render the suggestion as an inline diff decoration. The text to be replaced is highlighted in red, while the new content is shown in green at the insertion point. This way, the user gets a clear preview of the change without moving the cursor.
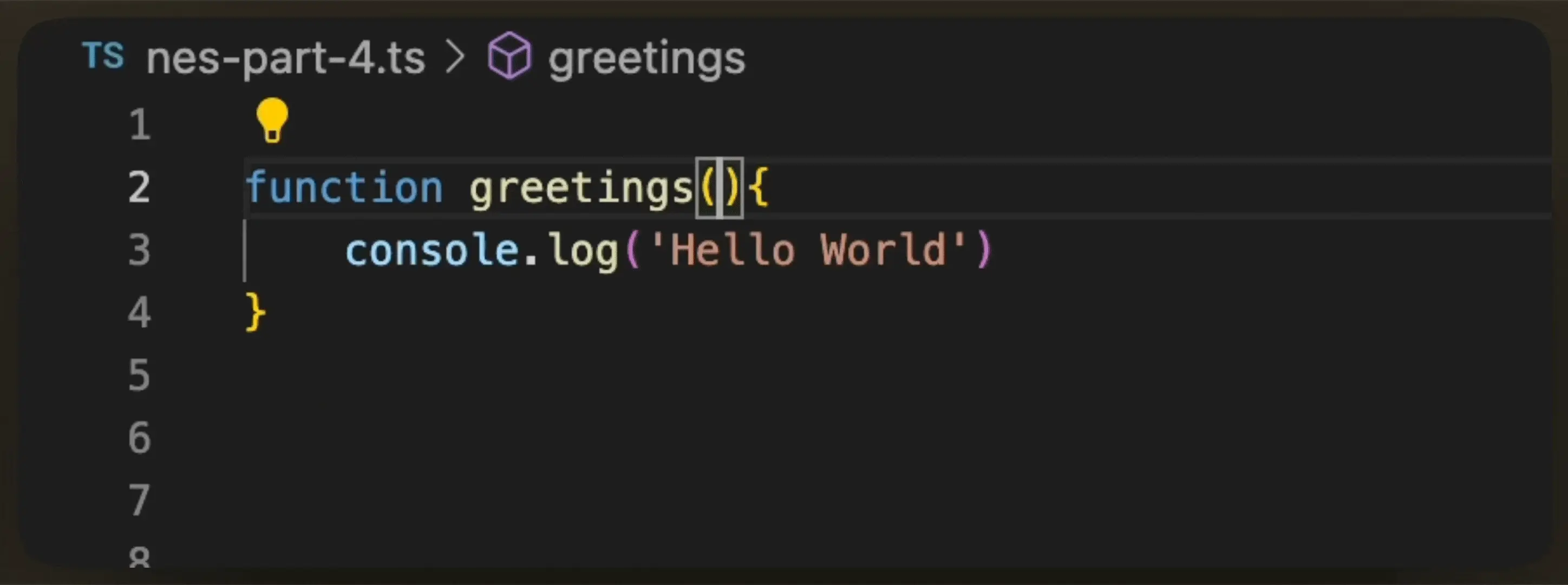
This works particularly well for changes involving single-line updates or even multiple lines where each line is being changed independently.
Floating Diff Image
Because NES has the ability to propose structural edits, such as inserting a new helper function, refactoring a block of logic, or adding a multi-line configuration, it frequently produces multi-line suggestions that cannot be represented as simple, inline changes.
In these cases, the suggestion is no longer tied to the cursor’s immediate context, and the standard inline rendering stratergies do not suffice.
At this point, the decision falls under either pulling the user away from where they’re working or bringing the preview to them. Since preserving developer flow is a core design principle for NES, we consistently choose the latter.
In order to make the suggestion appear near the edit target without moving the cursor, we generate a floating diff preview and render it as an image. The color schema of the suggestion will also stay consistent with the other solutions we discussed previously - red for deleted text, and green for inserted ones.
VS Code allows extensions to attach image-based decorations. With careful layout and positioning, these decorations can be floated near the edit target and used as a diff preview. However, the editor does not render code into images, which means the preview has to be generated by the extension itself.
This required a small rendering pipeline:
-
Theme matching: Every VS Code theme is an extension with a standard JSON format. We parse the active theme, extract its token colour map, and match it to the user’s active settings so the preview matches the theme in the editor.
-
Syntax highlighting: VSCode includes a bundled
TextMateruntime. We load the grammar for the current filetype, generate syntax scopes, and apply the same colouring rules that VS Code uses. This ensures that the rendered code maintains the same appearance as the code in the editor. -
Image rendering: Here we use
canvaskit-wasmto render the tokenized code into an image. To draw the code properly, we took the editor’s currentfontSizeandlineHeight, drew each tokenized segment at the correct coordinates, then applied diff highlights (additions in green and removals in red). The final image is then surfaced using the decoration API.
This approach allows multi-line edit suggestions to appear near their target location while preserving cursor position and avoiding viewport jumps.
Conclusion
Different kinds of edit suggestions need different presentation strategies, with the editor API playing a decisive role in shaping the final experience.
Rendering an NES suggestion ended up being less about displaying text and more about maintaining the reader’s attention. Because no matter what, once attention is broken, even the best suggestion gets ignored.
Each rendering path is designed to stay as close as possible to the developer’s flow while working within the editor’s interaction model.
At this point in our journey, NES can decide what to suggest (the model), when to surface it (request management), and how to show it without disruption (rendering paths). Combined, these layers define how AI-generated edit results become truly helpful in a real IDE.
Weekly Update #17
Jan 02, 2026
TL;DR
This release we focused on improving how you review, refine, and iterate on agent-generated code inside VS Code.
We also targeted some bug fixes that increased correctness and stability during multi-step agent runs.
Let’s dive in!
🚀 Features
-
Reviews (Inline Comments) in VS Code: You can now review and refine agent-generated code directly inside the editor using Reviews.
Reviews let you leave inline comments on the diff, tied to exact files and line numbers. Instead of re-explaining issues in chat, you can mark multiple problems across the code and submit them together as a single review. Pochi uses this line-level context to apply fixes in one focused revision pass.
This is not a PR review system. Reviews are private, pre-PR discussions with the LLM, attached directly to code while you’re still iterating. #922
-
Select Base Branch When Creating a Git Worktree: You can now choose a base branch when creating a new Git worktree in VS Code.
Previously, worktrees were always based on the current branch (
HEAD), which could lead to accidental branch-on-branch workflows. Now you can start clean frommain(default) or any other branch. #864
🐛 Bug Fixes
-
Improved Problem Detection in File Writing Tool Calls: Fixed an issue where problems introduced and resolved across multiple file edits were not reported correctly to the agent. Diagnostics are now compared before the first edit and after the final edit, ensuring resolved issues don’t confuse subsequent agent reasoning. #915
-
Fix Missing Tool Call Checkpoints: We also fixed an issue where tool call checkpoints could be missed due to checkpoint generation happening before streaming completed. Checkpoints are now generated after the stream finishes, ensuring all tool calls, including the final one, gets properly recorded. #911
🔥 Preview
- We’re working on previewing tracked user edits directly in the input chat before prompting, and a guided auto-layout intro that explains which editor settings Pochi modifies (layout keybindings, panel behavior, auto-save, conflicting extensions), with the ability to opt into only what you want.
Weekly Update #16
Dec 25, 2025
*
/ \
/ 0 \
/_____\ // Merry Christmas
| // May all your builds be green
|TL;DR
This release is still in progress, but here are some early previews of what’s coming.
Also, starting this week, along with weekly updates, we’ll now include key debates and decisions happening inside the team. If you want a voice in what ships, do reply to us in the links given below.
🔥 Preview
-
Inline LLM comments are in the works. Leave notes on specific lines and the agent responds in context. These aren’t PR review comments, they’re AI discussion threads attached to code.
-
You'll soon be able to choose the base branch when creating a new worktree, instead of being forced to use the current branch (
HEAD). This makes it easier to start clean feature branches from main or any branch you prefer.
📖 Resources
- We published Part 3 of our NES series, covering how we handle model requests while a user is actively typing. Read the full blog here.
🤓 Internal Tech Discussions
-
Do AI coding agents review the wrong coding step? We’re debating a shift in how coding agents should be reviewed. Most tools pause the workflow to approve a plan before execution.
But in practice, plans happen before the agent has paid the cost of reality: before navigation, failed tests, dependency issues, and edge cases. The result is confident speculation, and not based on insights.
We believe that the real checkpoint should happen after the work: reviewing the walkthrough, the diffs, what broke, what got fixed, and why. That’s much closer to how engineers review code today. We’re debating this direction and would love your input.
-
AI coding conversations should be append-only: Instead of editing past prompts, the idea is to keep the history intact and fork from earlier points, similar to branching in Git.
Editing history might feel convenient, but it erases the reasoning, the failed attempts, and the learning that happened.
Read the full post and tell us what you think!
NES Series (Part 3): The Request Management Lifecycle Under Continuous Typing
Dec 22, 2025
In Part 1, we talked about how we trained our NES model to predict the next meaningful edit you’re likely to make in your code.
In Part 2, we then covered what the model takes as context to make this edit. This included deep dives into editable regions, user’s edit history, and using the overall project context.
Together, these two pieces (model + context) form the core intelligence foundation of the NES system. But incorporating them into an end-to-end real-time engineering system requires more thinking about real developer coding behaviour.
A code editor is a continuously changing space. Developers type, pause, delete, move the cursor, undo, redo, and essentially keep editing, often faster than any model can respond. Even a fast model call involves network latency, debouncing delays, server-side scheduling, and decoding / streaming time.
If not careful, a request that was correct when it was sent can return a response that arrives a few hundred milliseconds too late. Which means now you end up with edit suggestions for code that no longer exists. This is something that’s termed “haunted” for being technically right but not at the right place.
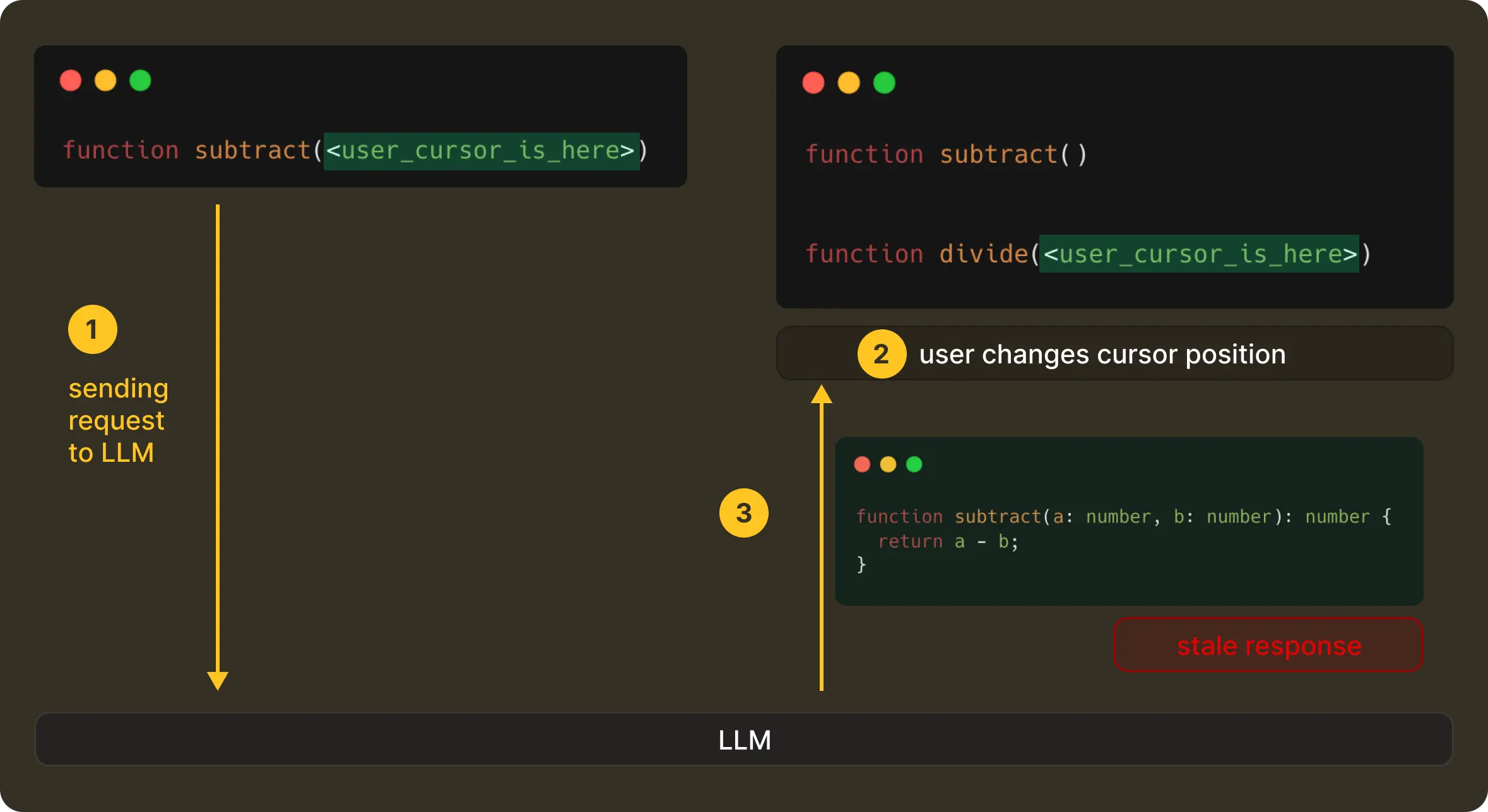
This means, in practice, a correct edit shown at the wrong moment is perceived as wrong by the user. So even with proper context and a good model, it is equally important to have the correct timing. Then only can the product actually feel useful without being distracting.
But getting timing right is challenging, due to the ever evolving nature of the user’s editing state. To make NES feel real-time and helpful, we had to reason about what happens before a request is sent, while it’s in-flight, and after the model responds. This is what we call request management.
Let’s look at it in more detail.
The NES Request Management Lifecycle
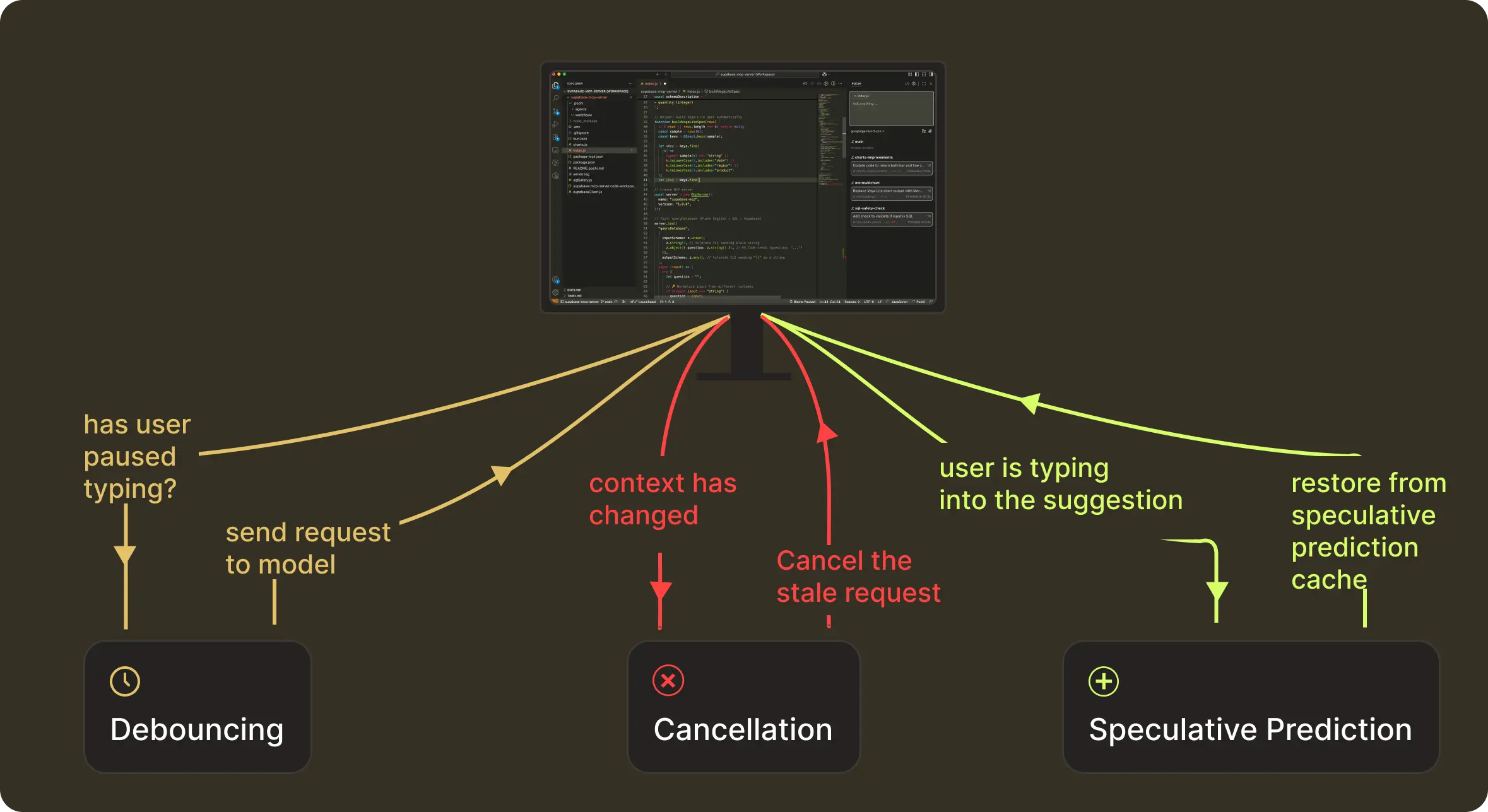
Request Management of a NES prediction happens in three stages:
- Before the request: waiting until the user actually pauses
- While the request is in-flight: discard anything that becomes outdated
- After the model responds: keep the suggestion alive if the user continues along the same trajectory
These map to what we technically implement as debouncing, cancellation, and speculative-prediction caching.
This structure helps bring the intelligent results (what we get with context + model) to users reliably, even as they type continuously. NES continues to run this loop as you type. Let’s take a closer look at how we handle timing at each stage.
Debouncing: Requesting the Model at the Right Moment
The first question we had to tackle was, “When is the right time to send a request?” When a developer is typing continuously, a request on every keystroke has little value and is wasteful. At the same time, waiting too long would make the system feel unresponsive and slow. We had to find that sweet spot that lies in detecting the exact moment the user actually paused typing.
Most systems solve this with a fixed interval, (say, 100ms), but real-world typing isn’t this predictable. Instead, we decided to adapt the debounce interval based on how the user is behaving right at that moment.
To achieve this, we made NES pay attention to a handful of lightweight signals.
For example, typing a . often means the developer is about to pause to access a method of an object, so we get the signal to shorten the debounce delay. Whereas, if the user is continuously typing through a variable name, we stretch the delay a bit to avoid jumping in too early. And if the model’s recent response times have been slower due to network conditions, we account for that too, so suggestions land at the exact moment the user expects them.
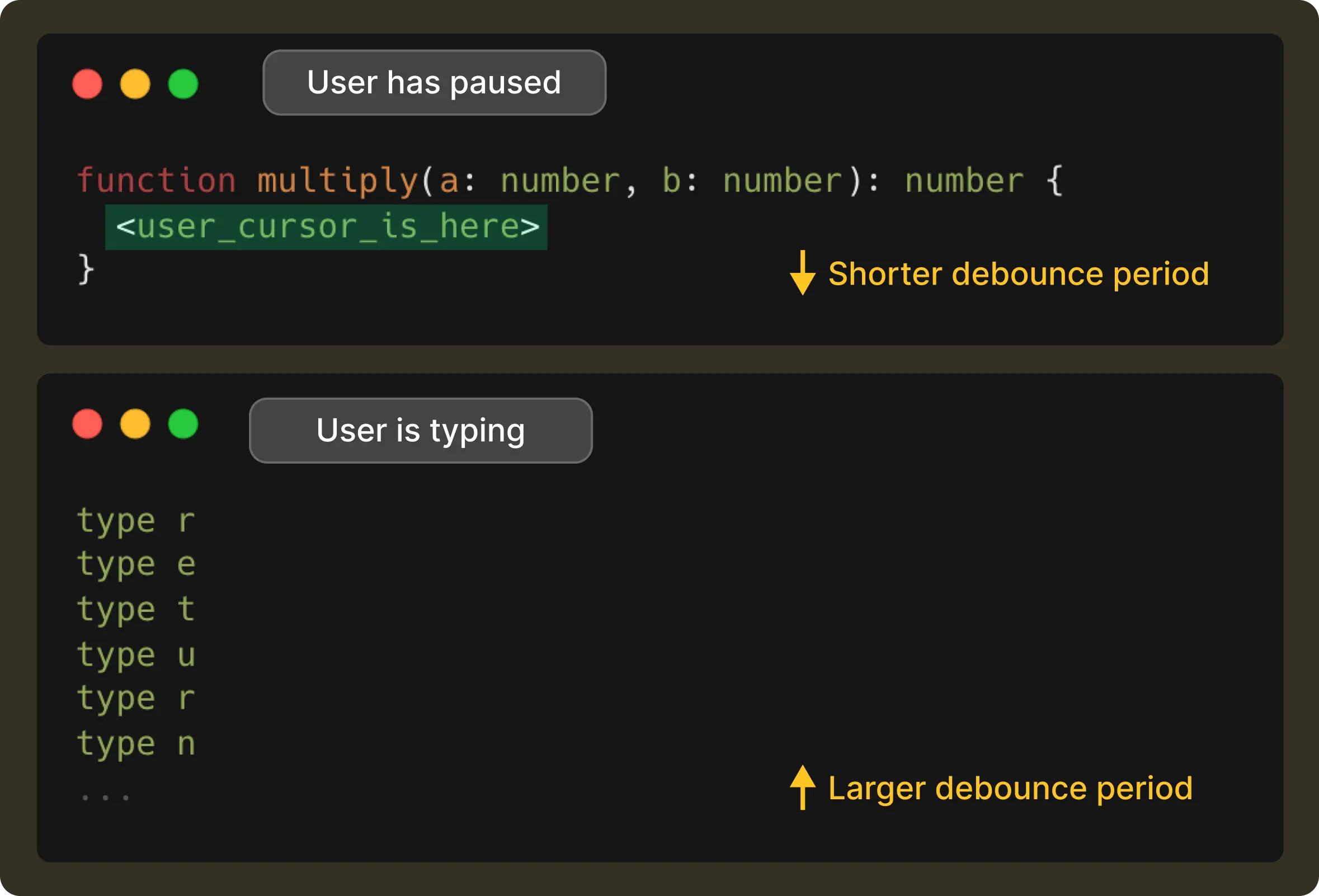 This way, the result is a debounce time window that changes with the user’s rhythm. It is short when the user has paused, and long when they’re in flow, all while making sure it never exceeds 1 second.
This way, the result is a debounce time window that changes with the user’s rhythm. It is short when the user has paused, and long when they’re in flow, all while making sure it never exceeds 1 second.
Cancellation: Correctness Over Completion
Once a request is finally sent, the editor doesn’t stop moving. A user can continue typing, move the cursor, or undo and redo steps before the model has even started responding. When that happens, the original request becomes stale instantly.
In such a case, we cancel the original request from the client-side, and in turn, the server propagates the cancellation, with any late responses being discarded without ever getting them rendered to the UI.
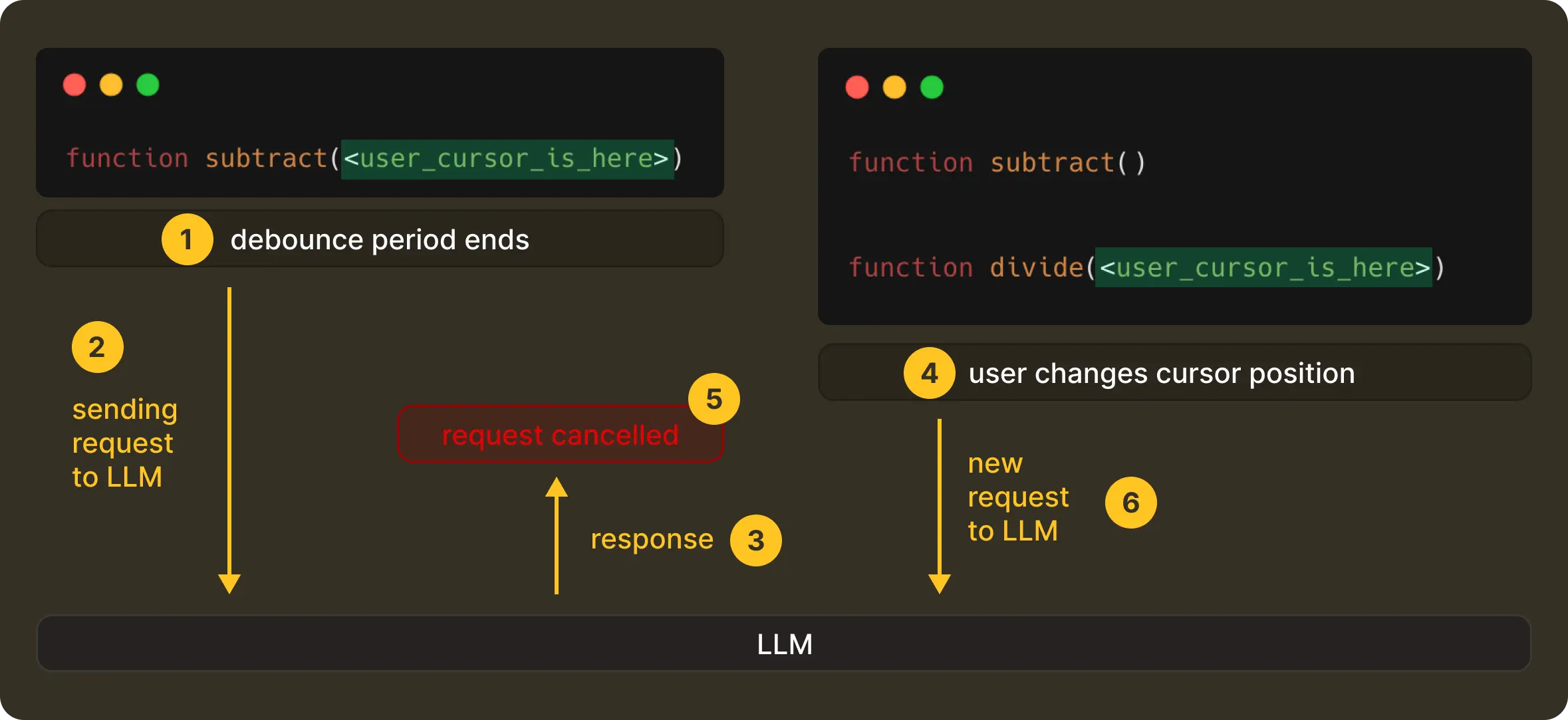 This is a deliberate design decision that optimises and enforces correctness in a live, ever-evolving editing system. We would prefer that NES show nothing rather than something misleading.
This is a deliberate design decision that optimises and enforces correctness in a live, ever-evolving editing system. We would prefer that NES show nothing rather than something misleading.
If you’re interested in how this works end-to-end, including streaming behaviour, we’ve written more about it here.
Speculative Prediction: Staying One Step Ahead of the User
Traditional caching is straightforward. If nothing has changed, just reuse the previous response. In the case of NES, this helps to avoid duplicate requests. And to think about it, throwing work away all the time would be expensive if we didn’t balance it out elsewhere.
But we go a step further. When the model returns an edit suggestion, we don’t just cache it for the exact context that produced it, but also speculate on the next few contexts the user is likely to enter.
Now, if the user continues typing along the same trajectory, NES doesn't need to call the model again and can continue serving the speculated suggestion. We call this speculative prediction.
A speculated prediction remains valid as long as the user is essentially still typing into the suggestion and the surrounding context hasn't changed.
It’ll be better to illustrate this with the help of an example. Suppose a user types:

NES sends a request and gets the following suggestion:

If the user then continues to type, resulting in:
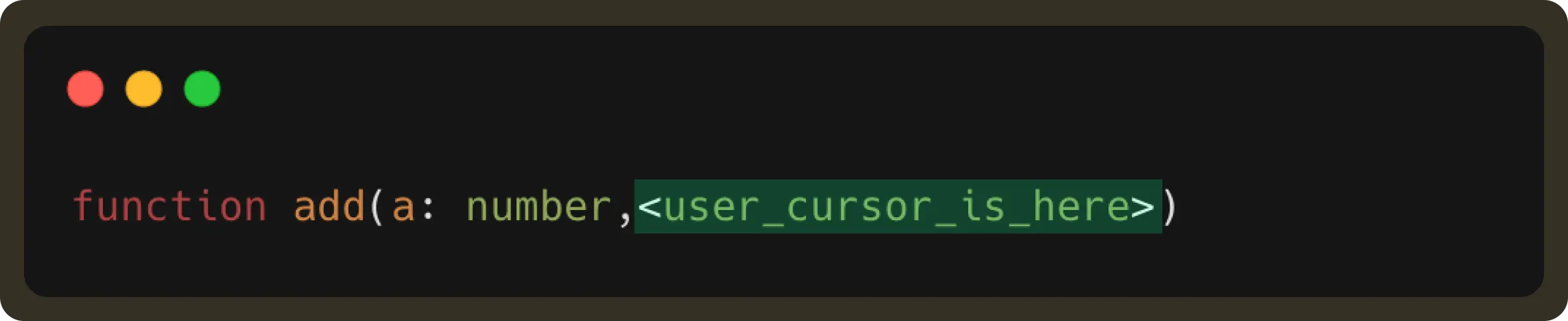
This user edit is part of the received suggestion. Therefore, the suggestion should still be displayed (unless the user has explicitly rejected it by pressing esc).
By retrieving this result from the forward prediction cache, we can display the suggestion faster and reduce LLM request usage.
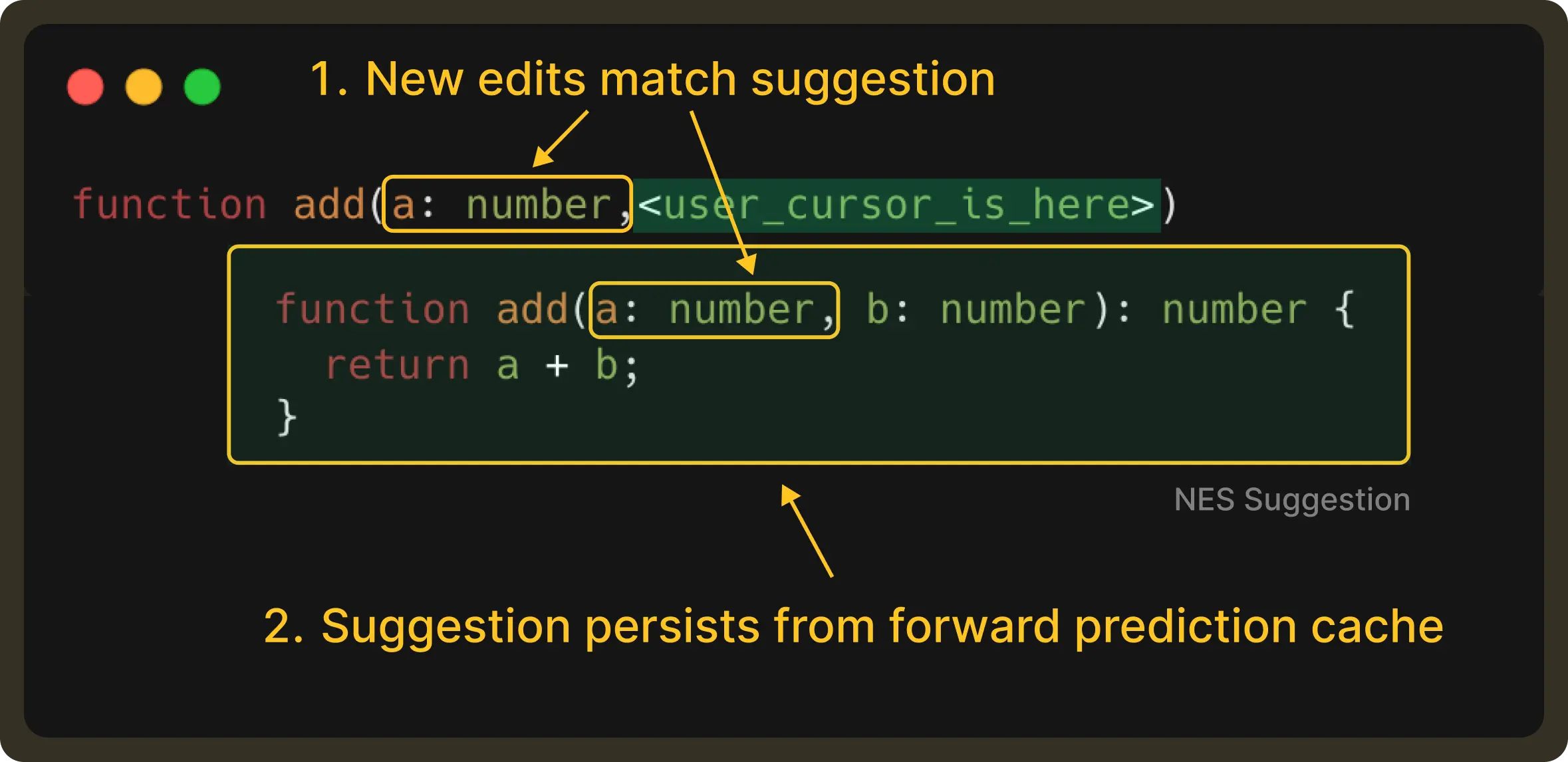
Of course, if the user is not satisfied with the cached suggestion, they still have the option to send a new request to get multiple choices. In essence, forward caching helps accelerate the common path, improving the overall experience.
Conclusion
By the time a suggestion appears in NES, a lot has already happened. Debouncing decides when is the right time to make a request, cancellation makes sure outdated intent never surfaces in the UI, and speculative prediction lets us reuse good existing predictions when the user naturally moves through them.
While you’d find these techniques are familiar in distributed systems, applying them inside a code editor was a challenge of its own. The primary driving factor wasn’t about throughput or load but about every evolving human intent under motion.
What’s next?
So far, we’ve focused on how NES decides what to suggest and when those suggestions should appear. With request management in place, we now have a system that ensures LLM-powered edits reach the user only when they’re truly helpful.
But now that brings us to the next stage of the process: How should these edits be presented?
NES suggestions aren’t always a single line near the cursor. Sometimes the relevant edit is several lines or even several files away. Presenting enough information for a quick action without breaking the developer’s flow is a surprisingly deep design and engineering challenge.
This is especially tricky inside a code editor like VS Code, where rendering options are limited. In such cases, how do we preview multi-line edits precisely? How do we make them feel lightweight, immediate, and skimmable, without being modal or disruptive?
In Part 4, we’ll dive into how we approached these constraints and built a rendering system that enables richer previews and lower-latency interactions for code edits.
Weekly Update #15
Dec 19, 2025
TL;DR
This week includes several improvements and bug fixes across the VSCode extension and Web UI.
A mix of workflow enhancements, UI polish, and reliability fixes landed. Here are the highlights:
✨ Enhancements
-
Improved Worktree Selector in VSCode Web UI: We’ve added support for creating a new worktree with an auto generated name directly from the dropdown; an additional way other than
Cmd+Entera prompt. We also included tooltips and renamedmainworktree toworkspacein the worktree list UI to better reflect its purpose. #896, #875 -
Open diff directly from a task: Clicking a task with diffs now opens both the task and its diff panel, making it easier to review changes directly from the task list. #849
-
Quick task creation from the Worktree sidebar: Added a
+button next to each worktree to create a new task. #877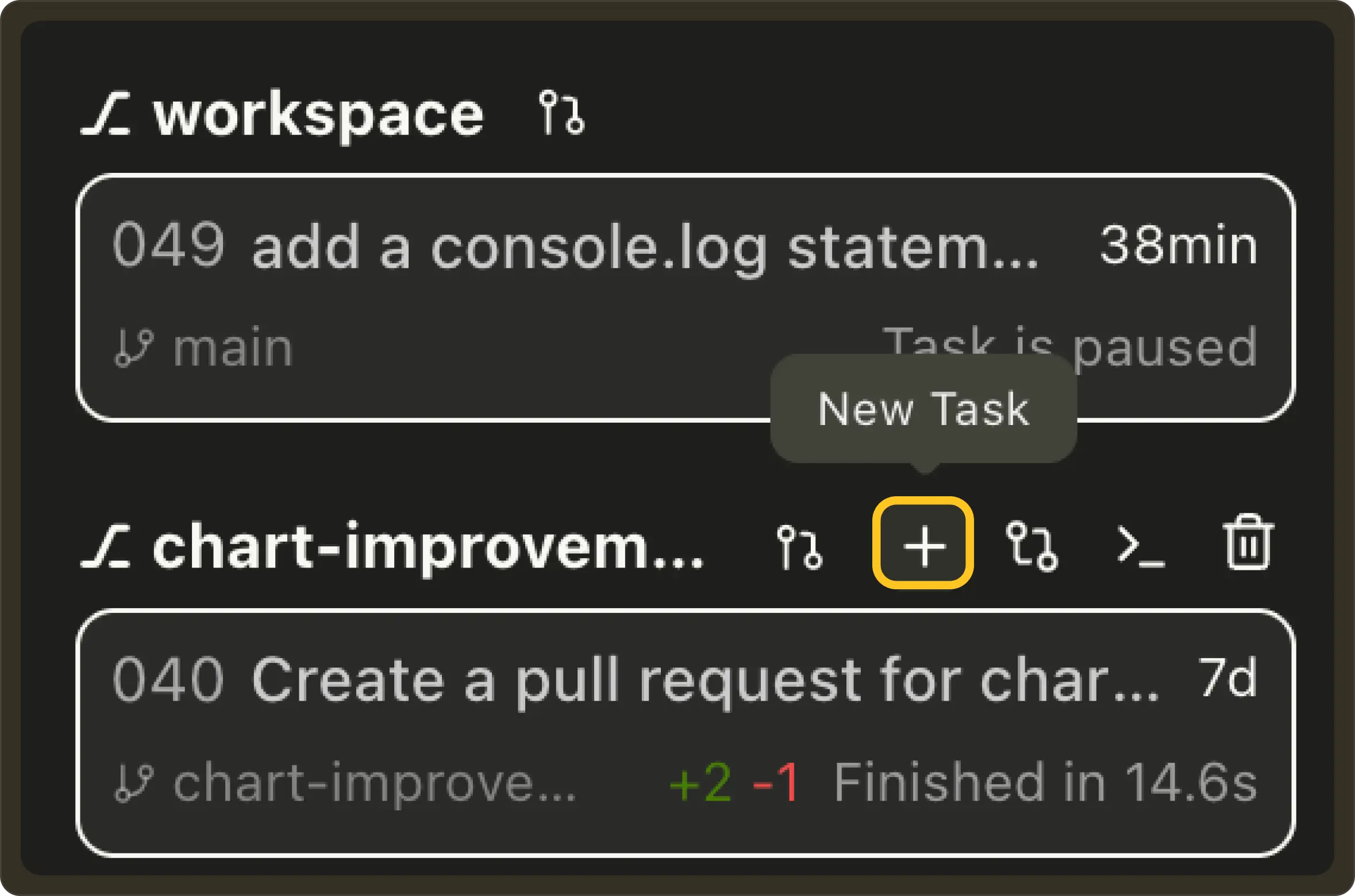
-
New keyboard shortcut: Added a
Ctrl+ ` keybinding in VSCode to instantly toggle the Pochi layout or open the terminal, improving keyboard-first navigation. This shortcut only exists as an advance configuration at the moment. To enable it, setenablePochiLayoutKeybindingin VSCode settingspochi.advancedsection totrue. #881🐛 Bug Fixes
-
Improved PR fetching reliability: Fixed the GitHub PR fetching logic to exclude pull requests from forked repositories, ensuring only relevant PRs from the main repo appear in the Worktree/PR selector. #893
Closing the Loop: How Reinforcement Learning is Changing AI Coding
Dec 12, 2025
TL;DR
Using SFT teaches models how to write code, but it is RL that is necessary to teach them what works. On the other hand, introducing RL in software engineering brings its own specific challenges: data availability, signal sparsity, and state tracking. In this post, we’ll break down how recent works address these challenges.

So far, the focus of RL driven improvements had been based on competitive coding. For example, in LeetCode-style tasks, the model works in a closed loop. It generally receives a clear problem statement and in turn, it generates a single, self-contained solution.
This means there are no dependencies involved, no files systems to navigate, and no legacy code that can break. It is exactly like solving a logic puzzle in isolation rather than understanding the engineering implications on the overall codebase.
However, the field of Software Engineering (SWE) in real-world is fundamentally different. It is a stateful, multi-turn interactive problem. A day-to-day involves much more than just writing the correct functions. You often need to navigate a file system, check up on dependency graphs, run the proper tests, and interpret logs in case of errors. This implies, an agent effectively needs to maintain coherence across a long horizon of interactions.
Which is why RL is an ideal candidate for SWE since agent actions produce verifiable results. At the same time, it also introduces challenges that are not present in single-turn tasks. For example,
- Data Availability: We cannot easily simulate millions of environmental interactions like we can with math problems.
- Signal Sparsity: Often, success signals appear at the very end of a long sequence of edits.
- State Tracking: Along with the static text of the code, the model must understand the dynamic state of the runtime environment
Recent works from Meta and Moonshot AI surfaced how the industry is pivoting from general reasoning RL to domain-specific SWE-RL to address these challenges.
The Data Problem
In order to learn trial and error, the standard RL requires an agent to interact with an environment. For coding, this means running a test suite or compiling code. As compared to verifying math proof, this simulation will be prohibitively slow and expensive in a real-world setting. Here, the engineering challenges arises to figure out how to bootstrap the entire learning process without being dependent on costly online simulation.
Meta proved that you can bypass the online bottleneck by using the massive offline history of Github. In its recent work on SWE-RL they talked through this approach instead of setting up a live sandbox for every training step.
But offline data lacks a reward signal. For every historical Pull Request, you cannot easily go back in time and execute tests. SWE-RL solves this by creating a process proxy reward. They calculate the fine grained text similarity between the generated patch and the actual developer ground truth solution instead of just checking if the code runs.
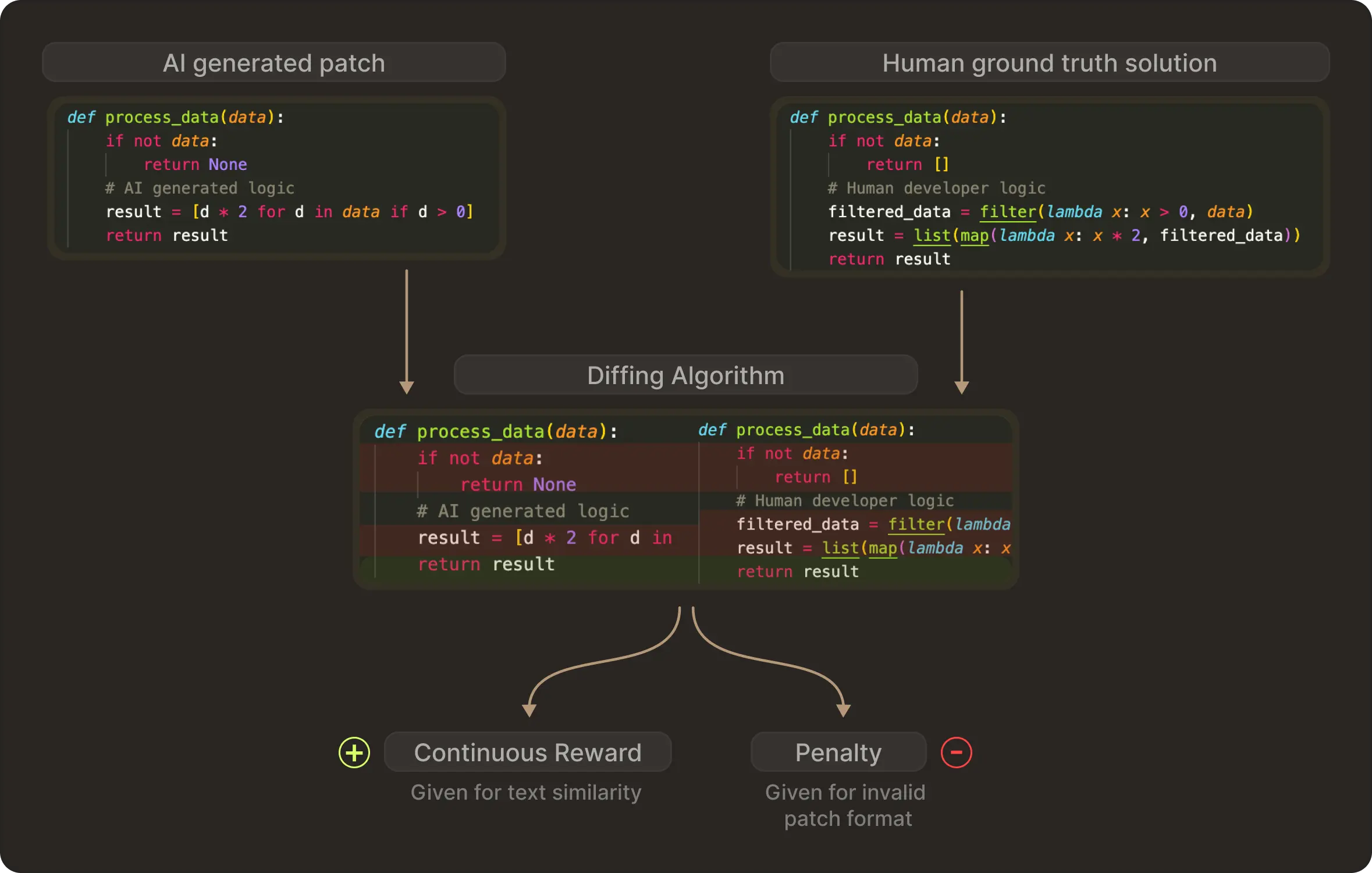
Depending on how closely the generated format matches the human solution, the model receives a continuous reward. On the other hand, if the model generates an invalid patch format, it receives a penalty. This demonstrates that even before touching a compiler, you can teach a model complex engineering behaviours like navigating file structures and adhering to project conventions using static history.
The Signal Sparsity Problem
Next, we have the credit assignment problem while facing online training within executable environments. That means it is difficult to indentify which step really contributed to the final success of the model and which step should get the reward. This reflects on software engineering as any agent can fail after 50 steps of editing and testing. Standard RL struggles to identify which specific step caused the failure.
The Kimi-Dev paper addresses this through task decomposition. It treats software engineering as a composition of atomic skills: the BugFixer (editing logic) and the TestWriter (verifying logic) instead of training an end-to-end agent to solve the issue immediately.
Their solution starts with Agentless RL. They train the model specifically on these short horizon atomic tasks using outcome based rewards. They look for signals on whether the patch passed the test or did the test reproduce the bug. And since the tasks are scoped down, the feedback signal becomes dense and clear.
Kimi-Dev shows that with minimal additional data, a model having these pre-trained capabilities can be adapted to a complex multi-turn agent framework. This suggests that the most efficient path to autonomous agents is rigorous skill acquisition’s followed by workflow adaptation rather than brute force end to end training.
The State Problem: Building a Code World Model
Coming to the final challenge, which is also arguably the most profound. Engineers generally do not just read code as text but also think about the execution loops in their mind. This involves tracking how variables change in memory and how functions interact between files. Meanwhile, since current code LLMs lack this internal compiler engine, they just merely predict the next token based on statistical likelihood.
Meta Code World Model addresses this by fundamentally changing the training curriculum. They realized that waiting until the RL phase to teach execution dynamics is too late. The rewards are too sparse and the gradient vanishes on hard problems.
Instead, in the mid-training stage, they inject process supervision directly. To teach the physics of code, they constructed two massive datasets:
-
Python Execution Traces: With over 120 million examples, the model is trained to predict not just the next line of code, but also the exact state of runtime variables (the values in memory) after every single line.
-
ForagerAgent Trajectories: Agents with 3 million trajectories that interact with a Docker environment to solve tasks.
This forces the model to internalise a Code World Model. By the time the model enters the final RL stage it is no longer starting from scratch. It already understands if I write X then variable Y changes to Z.
Consequently, the RL stage becomes a process of Goal Alignment. It uses sparse result rewards like passing tests simply to guide a model. It already understands execution physics to select the specific path that satisfies the verification requirement.
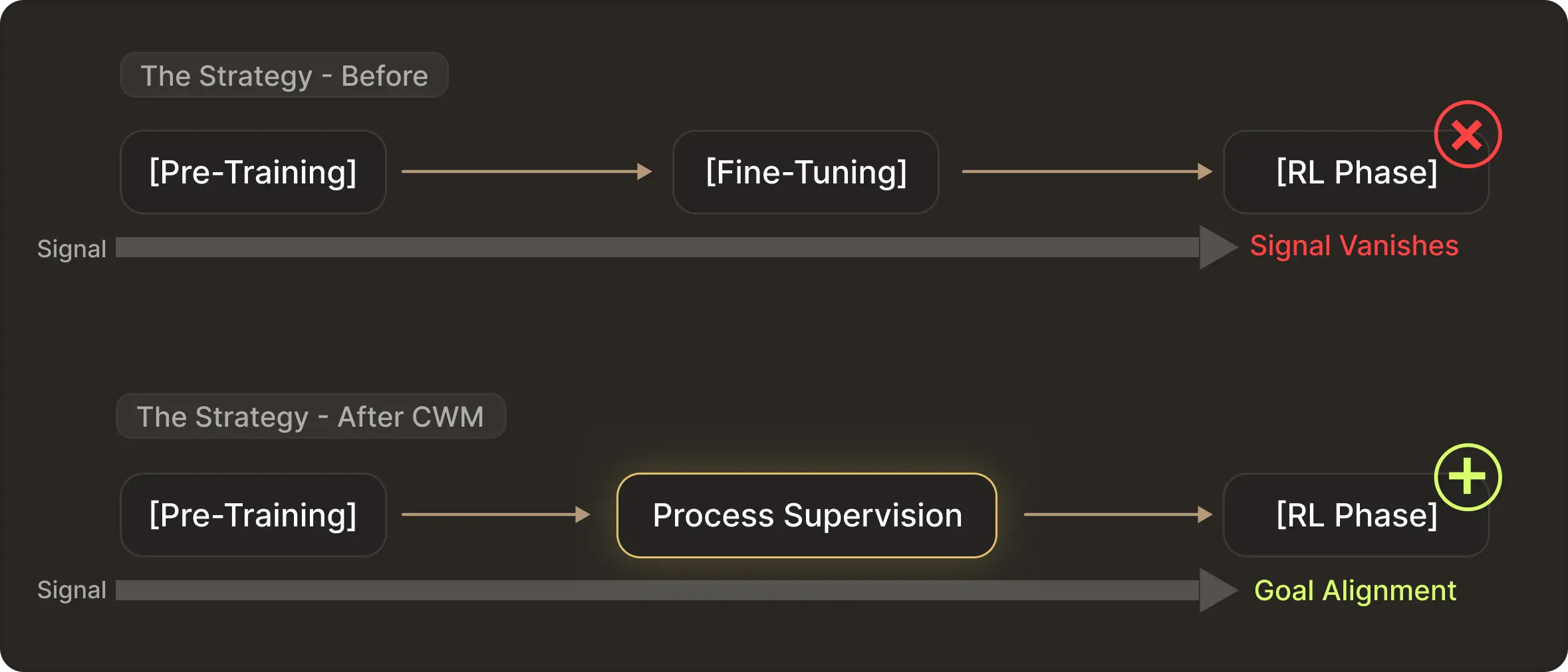
Takeaway: Moving Toward Verifiable Agents
This progression from SWE-RL (offline proxy rewards) to Kimi-Dev (decomposed skill learning) and CWM (execution-trace world models) outlines a clear engineering roadmap for the next generation of code models and agentic RL frameworks.
We are seeing a shift from generic reasoning to specialized engineering. Future models will be more than just smart. They will be grounded in repository history, capable of self-verification through test writing, and possess an explicit internal model of runtime state.
At TabbyML we view these developments as the foundation for Verifiable Engineering. The future value of AI in software development lies in building agents that understand and respect the state of your system.
Related Papers:
- SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
- Kimi-Dev: Agentless Training as Skill Prior for SWE-Agents
- CWM: An Open-Weights LLM for Research on Code Generation with World Models
Weekly Update #14
Dec 11, 2025
TL;DR
This release introduces pair of upgrades aimed at making Pochi feel even more native to your development flow: GitHub Issue integration embedded right into task input, and a new Cmd/Ctrl + Enter shortcut to spin up worktrees easily.
🚀 Features
-
GitHub Issue Integration in Task Input: You can now connect tasks directly to GitHub Issues. Typing
@#opens an inline issue selector where you can search by issue ID, keyword, or scroll the dropdown list.All newly created issues are accessible within a minute. Once selected, issues appear as markdown badges and are sent as enriched context to the model.
Note: This feature requires GitHub CLI to be installed and authenticated. #833
-
Create a New Worktree + Task with
Cmd/Ctrl+Enter: You can now start a brand-new worktree and task instantly usingCmd+Enter(macOS) orCtrl+Enter(Windows/Linux). When you submit a prompt with this shortcut, Pochi automatically creates a new worktree with an auto-generated branch name (based on the task description, falling back to a timestamp when needed) and launches a new task inside it.The shortcut also works when submitting messages with file or image attachments. In existing tasks,
Cmd/Ctrl+Entercontinues to queue messages as before. #822
NES Series (Part 2): Real-Time Context Management in Your Code Editor
Dec 05, 2025
In Part 1, we covered how we trained our NES model, including topics such as the special tokens we use, the LoRA-based fine-tuning on Gemini Flash Lite, and how we utilized a judge LLM to evaluate the model.
However, the end experience is far more than just building a good model. To make NES feel “intent-aware” inside your editor, we needed to give the model the right context at the right moment.
In part 2, we’ll talk about that runtime system, or to be precise, how Pochi manages, ranks, and streams real-time edit context. This is the core that helps NES to understand your intent and predict the next meaningful change.
Why Context Management Matters
To start, let’s understand what context management is. In our case, it’s the layer between when a user starts typing and when the model is called with a well-formed prompt. During that in-between phase, the system gathers and prepares all the relevant context the LLM needs before we make a model request.
As to why it matters, imagine simply sending the entire file to the model on every keystroke. Not only will the model become slower and noisier, but you’d get unstable predictions and over 20 model calls per second, rendering the whole experience unusable.
Instead, as previewed in the first article, we provide NES with three kinds of context:
- File Context: text, filepath, cursor position, and the region to be edited
- Edit History: record of recent edit steps
- Additional context from other files (optional): e.g., functions/type declarations that help understand the current file
Each of these depends on clever filtering, segmentation, and timing - all of which happen in milliseconds during normal typing, as we’ll learn below.
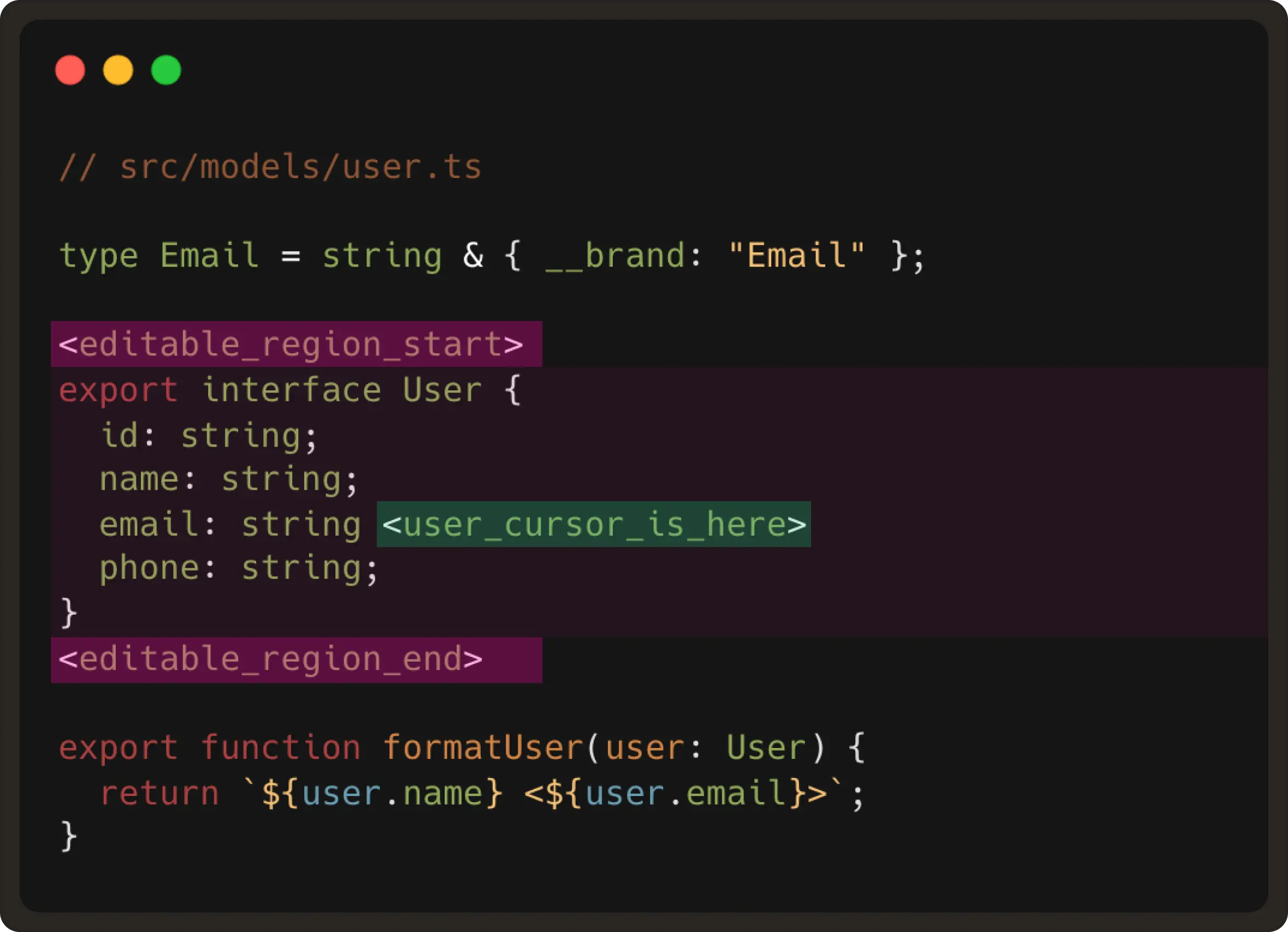
1. File Context: Finding the “live” region of code
The first question to solve: “Where is the user editing right now?”. This is the foundation of every NES prompt. We answer this by gathering three quick pieces of information from the VS Code API:
- The current file text
- The file path
- The user’s cursor position Using this information, we compute what is called “the editable region”. This region is generally a small code window around the user’s cursor of ~10 lines.
Why ~10 lines?
Because realistically, the next edit will almost always happen very close to where the user is already editing. This small window keeps the latency extremely low and is large enough to capture the structure around the edit.
And while we observe many models are over-eager and hallucinate changes elsewhere, our model is prevented from rewriting parts of the file the user wasn’t touching.
An example of the editable region would be:
2. Edit history: Following the user’s intent over time
So far, we have learnt where the user is currently editing, but we also need to understand how the code is changing over time. This is the part where edit history becomes important for the edit model to predict the user’s intent.
Now, while we could use the VS Code API to register a listener for text change events, this ends up triggering an event for almost every keystroke. For example, if a user updates a type from string to email, it ends up producing ~6 events.

These are not your meaningful edit steps. If we send this to the model, it will think each keystroke is a new “user intent” and will fire too many requests with wildly different predictions. Instead, we reconstruct real edit steps using an internal change segmentation grouping.
How we group events into meaningful steps
Since we cannot directly use the listener events, we decided to reduce them to events that represent edit steps. To achieve this, we group raw text-change events into undo-redo scale units.
Most editors record undo-redo steps on a word scale - for example, when a user inputs a sentence, an undo action will revert the last input word. In our case, for building edit prediction prompts, we do this on a larger scale.
- Once we receive information on a user’s cursor position and tracking gets initiated, we create an edit steps list, where each step is an accumulation of several text change events. We found that 5 steps is the sweet spot to build a prompt. Anything more than that adds noise, and if less, loses the intent.
- For each received text change event, we check if it is adjacent to the previous one. If yes, it belongs to the same edit step; otherwise, if it happens in a different part of the file, we consider it as a new edit step.
So continuing our example from earlier, if the user happens to add a
validateEmailfunction next, we now have two edit steps in tracking.
The first edit step:

The second edit step:
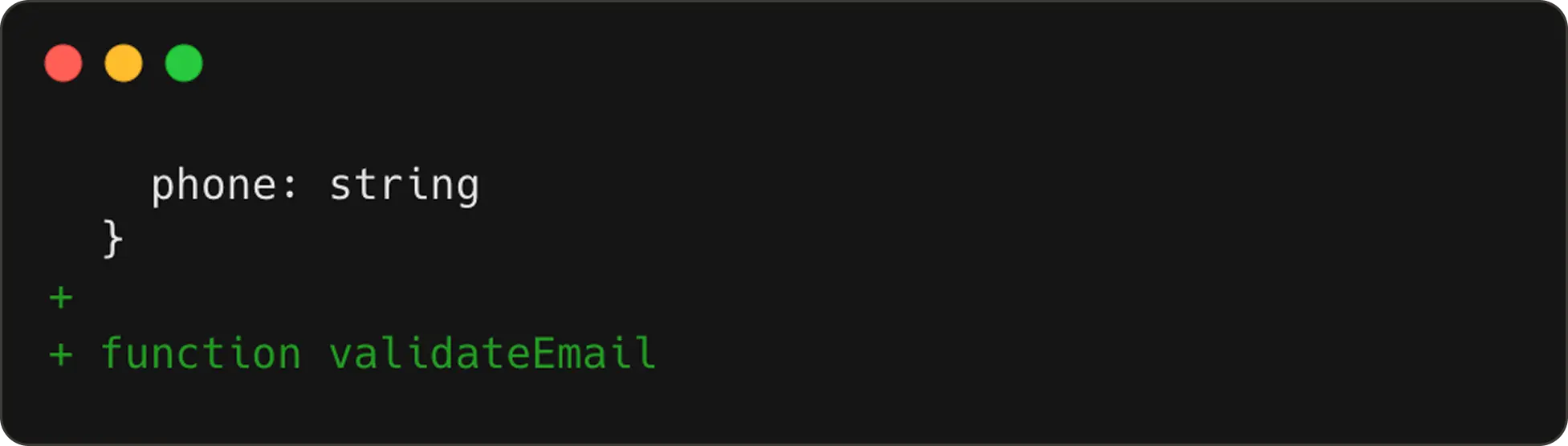
NES receives these steps wrapped inside <|edit_history|> token to learn how the code is evolving.
Special Case: Git Checkout Noise
One edge case we uncovered is when users run git checkout to switch branches. This triggers massive file changes, none of which represent real user intent. If we were to treat these as edit steps, the model would end up thinking the user rewrote half the codebase. In order to avoid polluting the model direction, we:
- Monitor the git status
- Reset edit history when it changes (
checkout,pull,stash) - Resume tracking after a few seconds
3. Additional Context: Bringing in the rest of your project
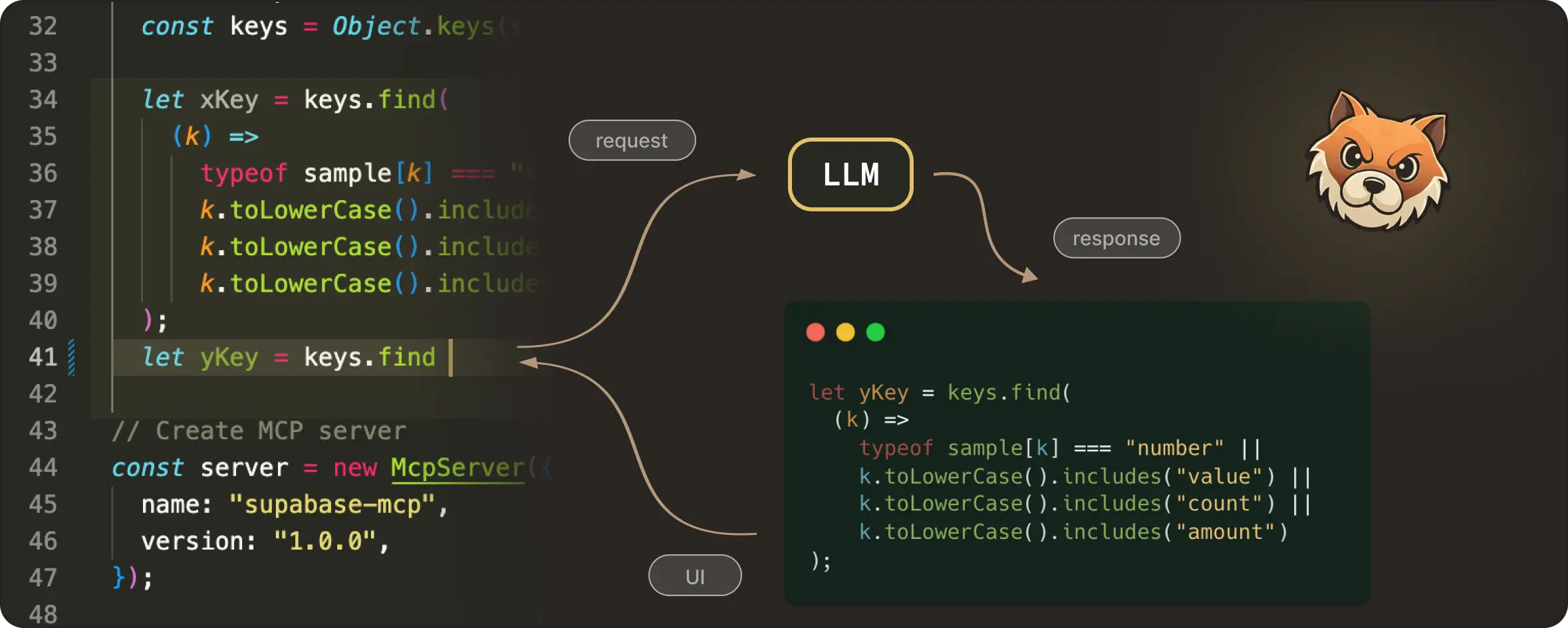
Code rarely exists in isolation. If you’re editing a function call, the model may need the definition. Likewise, if you’re modifying a type, the model may need the type declaration.
To give NES this kind of project-aware understanding, we pull additional snippets using the user’s installed language server. For this, we have two VS Code / LSP APIs:
- We use
vscode.provideDocumentRangeSemanticTokensto scan the editable region for each token type. Then we can find the tokens of interest, like a function, interface, or type defined in another file. - Next, we use the VS Code command
vscode.executeDefinitionProviderto get the target location for the definition code snippets. This is likeCtrl/Cmd+ clicking on a function to see the definition in another file.
These two commands are provided by the language server (LSP), which should be available when the language plugin is installed in VS Code. We then extract the definition snippet and include it in <|additional_context|> token as shown below:
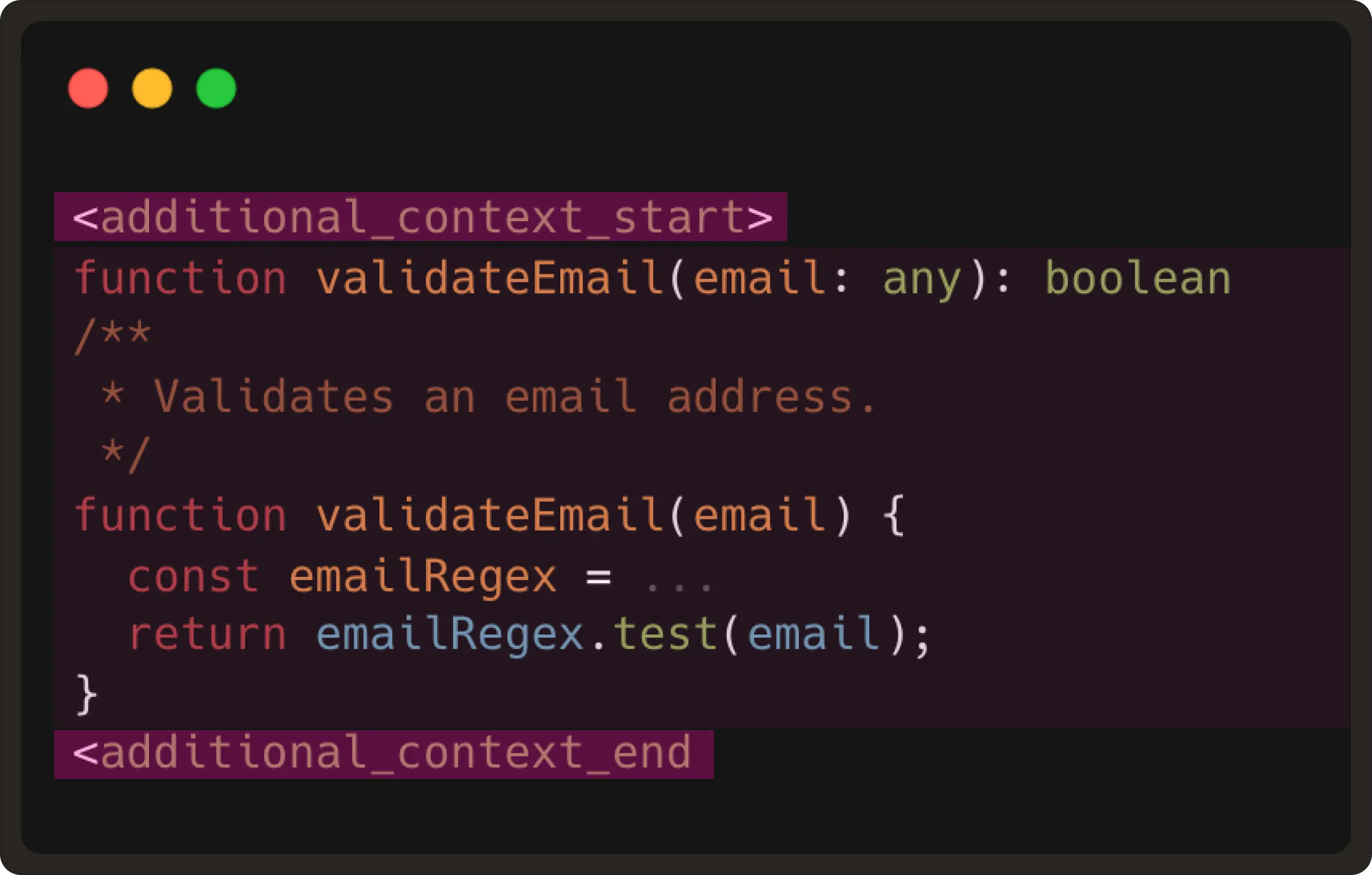
This gives the model the same context a developer would mentally reference before typing the next edit.
Note: We do realise that some of the functions could be huge or a type might be hundreds of lines, with LSP sometimes returning entire class bodies. Therefore, to throttle/limit semantic snippet extraction, we’ve currently hard-coded a maximum of 2000 characters per snippet for now.
Meanwhile, in cases where good LSP support is lacking, like plain text, we don’t add any related snippets context to the prompt. Instead, the prompt will still contain the prefix, suffix, and edit records.
Putting It All Together
As learned above, every NES request contains the <|editable_region|>, <|edit_history|> and <|additional_context|> tokens.
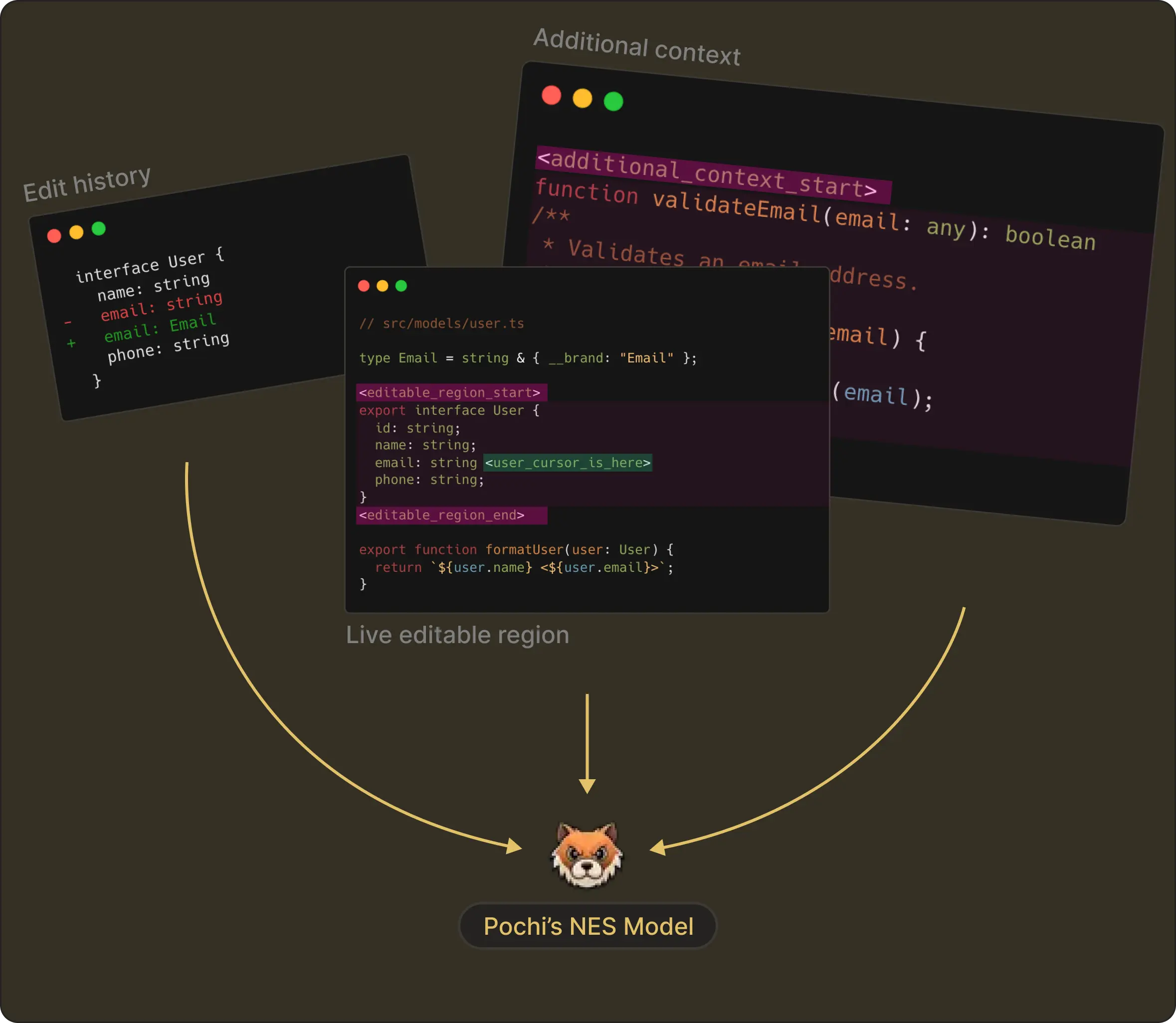
At the end, each piece is carefully constructed into the model exactly the way it was trained. This symmetry between training and runtime makes NES far more reliable than native autocomplete-style approaches.
What’s next?
In our next post, we’ll talk about Request Management, the system that ensures the model never gets a chance to be wrong about the user’s current context.
We all understand real coding experience involves a lot of short, focused typing, moving the cursor to different places, and continuing to edit while a request is still in flight. This means the model requests can become outdated before their response arrives, or worse, it might produce suggestions for code that no longer exists.
One of the reasons NES feels fast is because everything that isn’t the latest user intent is thrown away immediately. This cancellation of stale predictions is one of the biggest reasons Pochi’s NES feels so smooth and accurate.
More on this in our Part 3 post. Read more.
Weekly Update #13
Dec 04, 2025
TL;DR
This release brings some of our most practical updates yet: GitHub PR creation directly from worktrees, the ability to fork tasks when an agent drifts, clean task resets when context gets too large, and UI improvements that make multi-worktree setups far easier to manage.
A small step closer to a more transparent, predictable coding agent.
🚀 Features
-
GitHub PR Workflow: Pochi now understands Pull Requests per worktree. You can create PRs directly from the sidebar, and each worktree shows its associated PR, status (checks running, ready to merge, failed), and a breakdown of CI/Lint/Test results with quick links. PR state persists across sessions and stays linked to your worktree. #747
-
Fork a task: You can now fork any task when things go off-track. If an agent drifts, a tool call fails, or you want to try a different direction, hit Fork to spin up a new task starting from the same point in the conversation. The original stays untouched.
This makes it much easier to debug issues, try alternative fixes, or compare multiple approaches side-by-side. One great use case would be to provide corrective feedback and guide the agent back on track without resetting the whole task. #455
-
Create a New Task with Previous Context: When a task grows beyond ~50k tokens, Pochi now suggests New Task with Summary option. This creates a clean task with a summary of the previous conversation, helping you avoid hitting context limits while keeping all relevant information. #779
-
Auto Layout: We added a new “Pochi Layout” toggle that instantly arranges your VS Code workspace into an optimized 3-pane layout: the Pochi task view on the left, code/diffs on the upper right, and terminals in a separate bottom-right tab group. This keeps terminal output isolated, prevents accidental layout shifts, and makes long-running tasks much easier to follow. #733
✨ Enhancements
-
Incremental Task IDs: Tasks now receive a simple incremental ID (
#001,#002, …) that is shared across all worktrees within the same Git repository. This makes tasks easier to reference while still preserving grouping by worktree in the UI. #746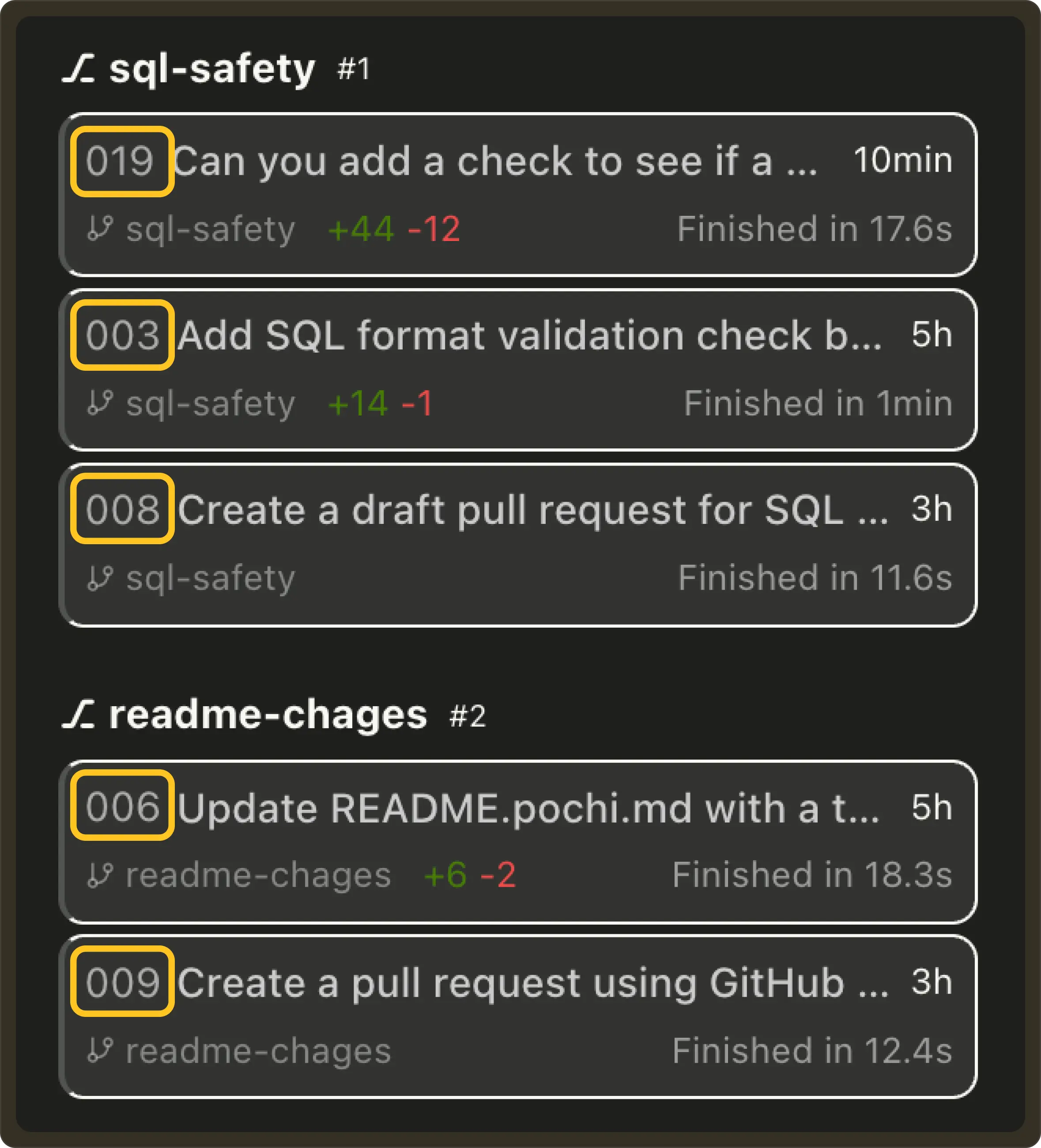
-
Optimistic Worktree Deletion: Deleting a worktree now updates instantly in the UI, making the worktree disappears immediately without waiting for the backend to confirm. This makes task management feel faster and keeps the sidebar in sync with your intent.
🔥 Preview
- We’re working on multi-worktree task execution (run tasks in parallel across branches or models) and GitHub/Linear issue linking that lets Pochi automatically attach, track, and close issues as part of your workflow.
Weekly Update #12
Nov 28, 2025
TL;DR
This weeks update is packed with improvements to task visibility, worktree workflows, and NES accuracy. We also made foundational changes to how tasks are stored, which sets us up for upcoming GitHub and multi-worktree features.
Breaking Change: Task list reset in v0.16.0
We introduced a breaking change in v0.16.0 that may result in the loss of the task list after upgrading. No action is needed as new tasks will behave normally going forward.
🚀 Features
- Diff Summary Panel for Task Changes: We added a diff summary panel inside each task, showing all file edits made during execution. You can now review per-file additions/deletions, inspect the total change summary, and undo changes directly from the panel itself. #728
✨ Enhancements
- Improved Visibility into Task Execution: Tasks now display real-time execution details, including active tool calls, subtasks, and streaming progress to make task behavior easier to understand at a glance. This brings much clearer visibility into what Pochi is doing while a task runs. #675
-
Tasks grouped by worktree: Pochi automatically groups tasks by their associated Git worktree with active worktrees at the top and deleted worktrees collapsed into a dedicated section. Each worktree shows its own tasks, status, and metadata which makes it much easier to manage parallel workstreams and multiple agents. #676
-
Diff Summary on Task List Item: Task rows now display git diff summaries (e.g.
+23 -5) so you can instantly see the size and impact of each task’s changes across multiple worktrees. #674
-
Worktree-aware task tabs: Pochi now opens tasks from the same Git worktree in the same VS Code tab group, and tasks from different worktrees in separate tab groups. This keeps parallel branches visually separated while you work. #677
- Unread Task Indicators: We added unread indicators to the task list so you never miss when a background task finishes or fails. Tasks that complete while you’re looking elsewhere now show a small dot until you open them, making it much easier to track updates. #673
- Enhanced NES prompting with additional local code context: NES now includes richer local code context in its prompt, improving accuracy for predictions that depend on nearby functions, variables, or imports. #727
🔥 Preview
- We’re actively working on GitHub PR creation and status, multi-worktree task execution, and GitHub/Linear issue linking - all designed to make Pochi even more powerful for real engineering workflows.
Weekly Update #11
Nov 21, 2025
TL;DR
This week was a big one.
We shipped Next Edit Suggestions (one of our biggest upgrades so far), along with real-time task notifications and cleaner diff views. Pochi now feels smarter, tighter, and much more intuitive across the codebase.
🚀 Features
- Next Edit Suggestions (NES): We’ve introduced our internal edit model powering Next Edit Suggestion (NES). It is an upgrade to Tab Completion that predicts the next change your code needs, wherever it lives. It learns from your recent edits, understands how your file is evolving, and auto-surfaces likely follow-up edits.
We’ve published a deep-dive on how we trained and evaluated the edit model, and how it powers Pochi's experience. You can read more here.
- Pop-up Notifications for Task Status Changes: Pochi now shows real-time notifications when a task completes, fails, or needs your input. Each notification includes a “View Details” button that jumps directly into the task. In the case the task panel is already open, we suppress duplicable notifications to reduce noise.
- Gemini 3 Support: We’ve added support for Gemini 3 Pro alongside 2.5 Pro. The UI for model selection is updated and ready for you to take over!
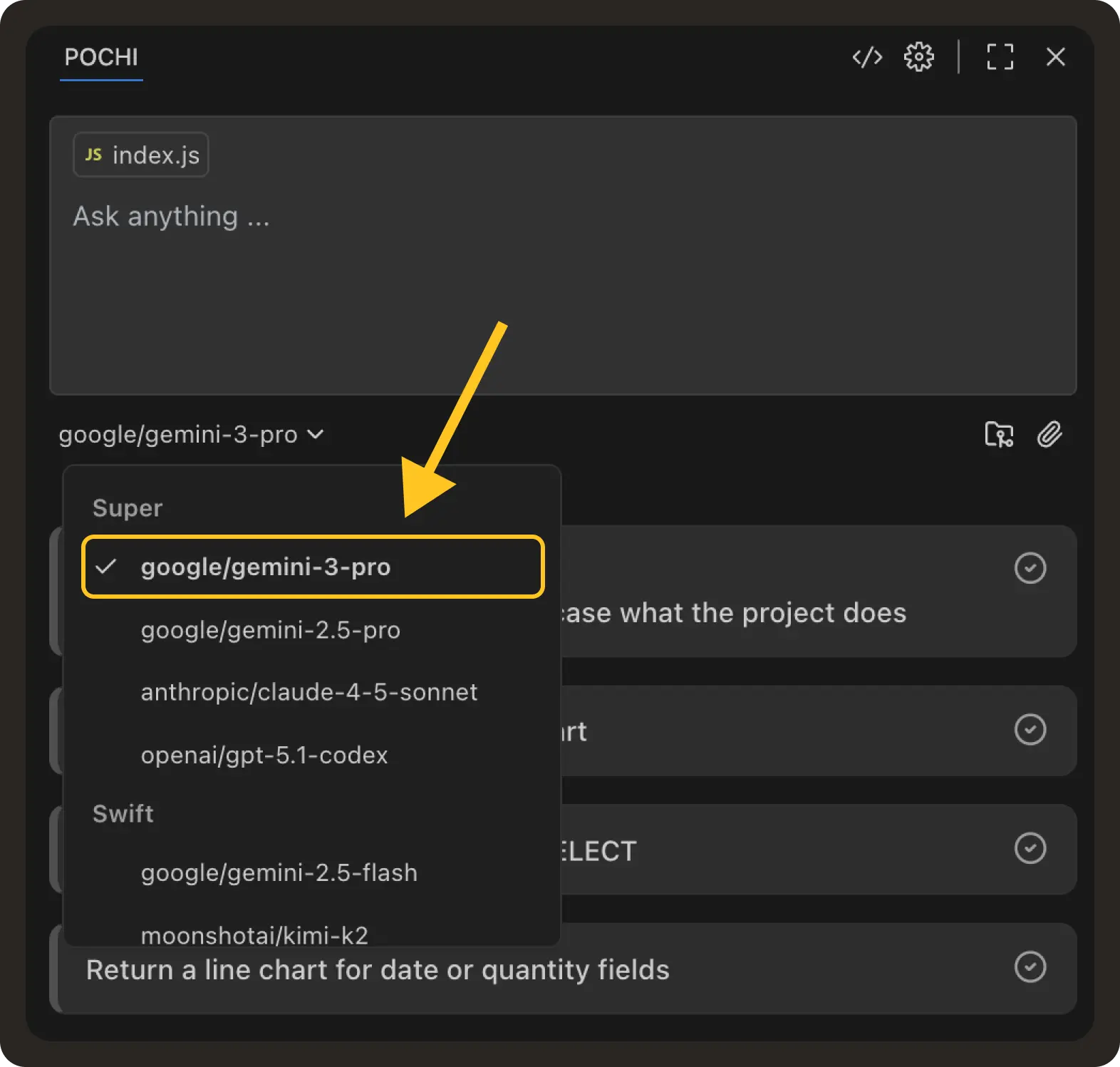
✨ Enhancements
- Line Wrap Toggle in Code Blocks: We added a line wrap toggle to the code block component in the VS Code extension. This way, long lines inside diffs and model edits are now way easier to read, especially when reviewing wide changes across generated code.
🔥 Preview
- We’re actively working on a set of UX upgrades for the VS Code sidebar - things like grouping tasks by worktree, cleaner task headers, and a diff-summary panel that shows all file edits at a glance. More on this in an upcoming update.
NES Series (Part 1): The Edit Model Behind Tab Completion
Nov 19, 2025
Note
This is a four-part series on how we trained and built our NES model at Pochi, covering everything from the edit model behind tab completion to real-time context management, request lifecycles, and dynamic rendering for AI code edits.
Read the full series:
– Part 1: The Edit Model Behind Tab Completion
– Part 2: Real-Time Context Management in Your Code Editor
– Part 3: The Request Management Lifecycle Under Continuous Typing
In this post, we’re introducing our internal edit model, the foundation behind Next Edit Suggestion (NES). It’s an upgrade to Tab completion, designed to predict the next change your code needs, wherever it lives.
Technically this is much harder to achieve, since NES considers the entire file plus your recent edit history and predicts how your code is likely to evolve: where the next change should happen, and what that change should be.
Other editors have explored versions of next-edit prediction, but models have evolved a lot, and so has our understanding of how people actually write code.
As an open-source team, we want to share this work transparently. This is the first post in our "Next Edit Suggestion" series, where we walk you through how we trained the underlying model to how it powers real-time editing inside the extension.
How We Train the Edit Model
When we decided to build NES, one of the first pressing questions on our mind was: What kind of data actually teaches a model to make good edits?
It turned out that real developer intent is surprisingly hard to capture. As anyone who’s peeked at real commits knows, developer edits are messy. Pull requests bundle unrelated changes, commit histories jump around, and the sequences of edits often skip the small, incremental steps engineers actually take when exploring or fixing code.
The Training Process
To train an edit model, we format each example using special edit tokens. These tokens tell the model:
- What part of the file is editable
- The user’s cursor position
- What the user has edited so far
- What the next edit should be inside that region only
Unlike chat-style models that generate free-form text, NES is trained to predict the next code edit inside the editable region.
Below is an example of how NES predicts the next edit:
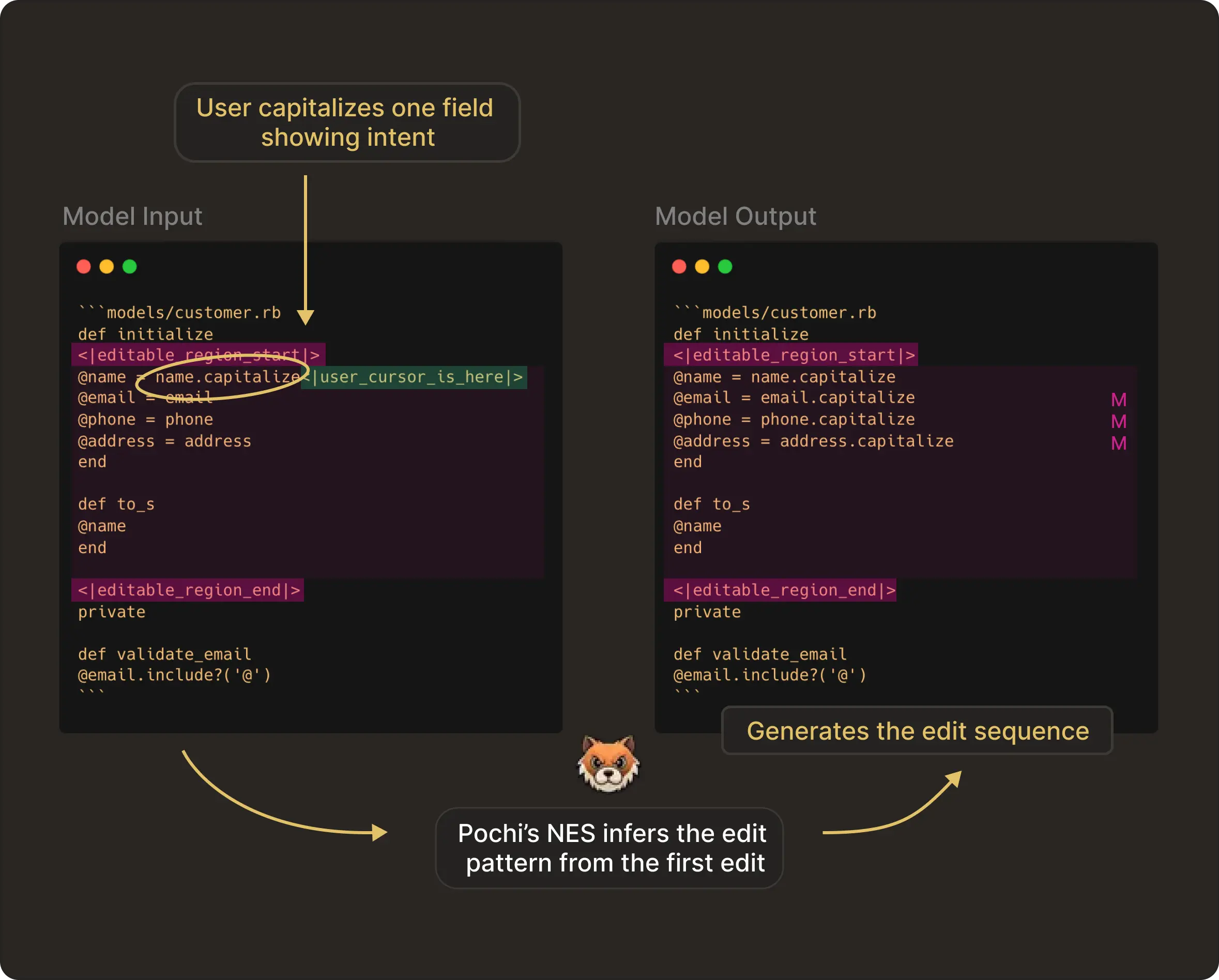
In the image above, the developer makes the first edit allowing the model to capture the intent of the user. The editable_region markers define everything between them as the editable zone. The user_cursor_is_here token shows the model where the user is currently editing.
NES infers the transformation pattern (capitalization in this case) and applies it consistently as the next edit sequence.
To support this training format, we used CommitPackFT and Zeta as data sources. We normalized this unified dataset into the same Zeta-derived edit-markup format as described above and applied filtering to remove non-sequential edits using a small in-context model (GPT-4.1 mini).
Choosing the Base Model for NES
With the training format and dataset finalized, the next major decision was choosing what base model to fine-tune. Initially, we considered both open-source and managed models, but ultimately chose Gemini 2.5 Flash Lite for two main reasons:
-
Easy serving: Running an OSS model would require us to manage its inference and scalability in production. For a feature as latency-sensitive as Next Edit, these operational pieces matter as much as the model weights themselves. Using a managed model helped us avoid all these operational overheads.
-
Simple supervised-fine-tuning: We fine-tuned NES using Google’s Gemini Supervised Fine-Tuning (SFT) API, with no training loop to maintain, no GPU provisioning, and at the same price as the regular Gemini inference API. Under the hood, Flash Lite uses LoRA (Low-Rank Adaptation), which means we update only a small set of parameters rather than the full model. This keeps NES lightweight and preserves the base model’s broader coding ability.
Overall, in practice, using Flash Lite gave us model quality comparable to strong open-source baselines, with the obvious advantage of far lower operational costs. We can , keeping the model stable across versions.
Why this matters for you
Using Flash Lite directly improves the user experience in the editor. As a user, you can expect faster responses and likely lower compute cost (which can translate into cheaper product).
And since fine-tuning is lightweight, we can roll out frequent improvements, providing a more robust service with less risk of downtime, scaling issues, or version drift; meaning greater reliability for everyone.
How we evaluated the model
We evaluated our edit model using a single metric: LLM-as-a-Judge, powered by Gemini 2.5 Pro. This judge model evaluates whether a predicted edit is semantically correct, logically consistent with recent edits, and appropriate for the given context. This is unlike token-level comparisons and makes it far closer to how a human engineer would judge an edit.
In practice, this gave us an evaluation process that is scalable, automated, and far more sensitive to intent than simple string matching. It allowed us to run large evaluation suites continuously as we retrain and improve the model.
Enhancing Context at Inference
Training and evaluation only define what the model knows in theory. To make Next Edit Suggestions feel alive inside the editor, the model needs to understand what you are doing right now. So at inference time, we give the model more than just the current file snapshot. We also send:
-
Your recent edit history Wrapped in
<|edit_history|>, this gives the model a short story of your current flow: what changed, in what order, and what direction the code seems to be moving. -
Additional semantic context Added via
<|additional_context|>, this might include type signatures, documentation, or relevant parts of the broader codebase. It’s the kind of stuff you would mentally reference before making the next edit.
Here’s a small example image showing the full inference-time context with the edit history, additional context, and the live editable region which the NES model receives:

NES combines these inputs to infer the user’s intent from earlier edits and predict the next edit inside the editable region only.
In this post, we’ve focused on how the model is trained and evaluated. In the next post, we’ll go deeper into how these dynamic contexts are constructed, ranked, and streamed into the model to drive real-time, context-aware edit predictions.
Weekly Update #10
Nov 13, 2025
TL;DR
We added modular @import rules and fixed PDF handling in readFile. Behind the scenes, we’re preparing two big improvements: smart task notifications and a refreshed, faster tab-completion experience.
✨ Enhancements
- Modular Rules with
@importSyntax: You can now split and organize large rule files by importing other markdown files using the@prefix (e.g.@./rules/api-guidelines.md). Pochi will stitch them together, managing complex configurations for your multi-agent or multi-project setups. #540
🐛 Bug fixes
- PDF Handling in
readFile: Resolved a bug that causedreadFileto return PDF files as plain text. #591
🔥 Preview
- Smart Task Notifications: Pochi will now show real-time notifications when a task needs your input, completes, or fails. Notifications will include a “View Details” button to jump directly into the task, and will be automatically suppressed when the task panel is already open to avoid duplicates.
- We’re also preparing an upgrade to our tab completion system to make suggestions feel faster and more intuitive. More details coming soon!
Launching Parallel Agents
Nov 11, 2025
Teams rarely work on a single task at a time. You might be part-way through a feature when a bug report arrives, someone needs a small refactor reviewed, or a documentation fix is pending. Most tools and workflows force these tasks to share one working state.
So you end up switching branches, stashing and popping changes, resetting your workspace, and trying to hold the original task in your head. This is context switching, and it’s one of the biggest hidden costs in software development.
We released Parallel Agents to remove that cost. Each agent runs in its own Git worktree, which isolates the task’s state from the rest of your work.
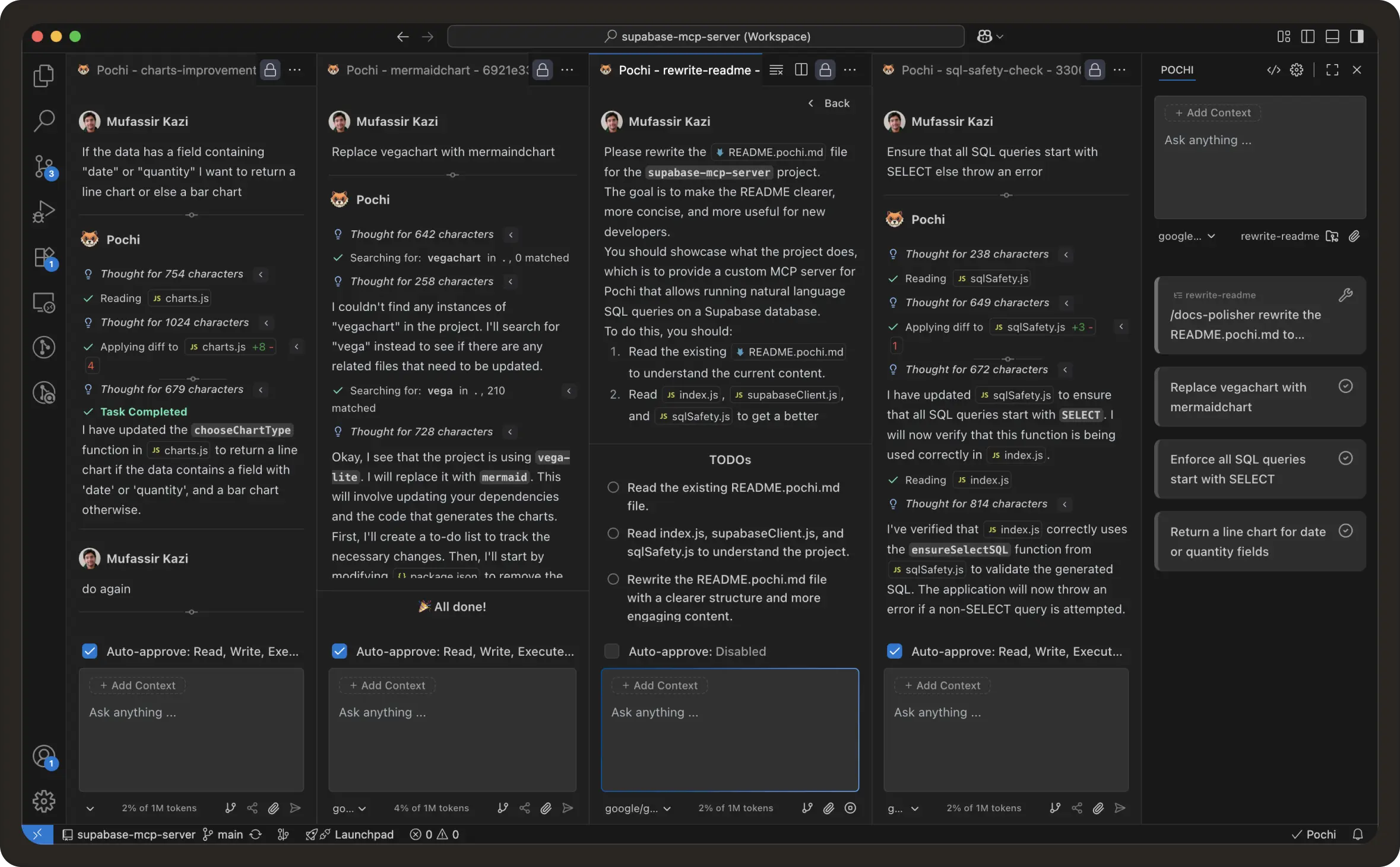
A great example would be to run the same task with different models to pick the best response. Won’t that be a faster and much better experience - all within the same timeframe?
This is different from other existing solutions, which operate inside a single editor tab. In those tools, you’re effectively working in one tab at a time: switching tasks means switching the state of the same working directory and the same conversation.
On the other hand, Parallel Agents in Pochi keep tasks fully isolated by running each one in its own Git worktree. You can keep multiple tasks active at once and switch between them without stashing or losing context.
How to use?
- You can create a worktree from the Pochi sidebar. Once a worktree exists, starting a task in that worktree opens it as its own tab in Pochi.
- When a task finishes, use the diff view to review its changes. If it looks good, create a PR from that worktree.
When to use Parallel Agents
Parallel Agents are most useful when you want to avoid breaking focus on ongoing work: quick bugfixes during feature development, long-running refactors that you want to keep separate, documentation changes that happen alongside coding, or letting an AI assistant explore broader changes in a sandbox.
On the other hand, if a change is meant to be reviewed and merged as a single unit, keeping it on one branch remains simpler.
Here is the demo showing the feature in action:
Read the full documentation here.
Weekly Update #9
Nov 01, 2025
TL;DR
Custom Agent gets even better ⚡ + i18n upgrades for global users 🌏! And major Chat Sidebar UX upgrades are coming soon! 🚀
🚀 Features
- Custom Agent with Slash Section: You can now invoke custom agents directly through slash commands in the VS Code chat sidebar — just like how you trigger workflows. #567
This change unifies how agents and workflows are invoked, creating a more intuitive and consistent experience for interacting with Pochi’s capabilities.
- Chat UI i18n: We are bringing full internationalization to the chat UI!✨ Hardcoded strings are being replaced with our i18n system (powered by
i18next), paving the way for a localized experience in English, Chinese, Japanese, and Korean. #201
✨ Preview
We’re actively working on a series of UX improvements to the VS Code chat sidebar, aimed at making Pochi more seamless and intuitive to use. Stay tuned for the upcoming update!
Weekly Update #8
Oct 21, 2025
TL;DR
We’ve given Pochi new tricks.
Workflows can now execute Bash commands, readFile tool handles multimedia inputs, and markdown rendering is faster and cleaner with streamdown.ai.
Let’s get on with it!
🚀 Features
- Bash Commands in Workflows You can now execute Bash commands directly inside Pochi workflows using the
!prefix. This allows workflows to pull live system or repository context, likegit statusoruname -a, and feed the results into the model before running your task.For example:
- With this: !`uname -a` and !`uptime`
- Please show the system info and uptimePochi automatically runs these commands and includes their outputs in the model’s context, making workflows more dynamic and connected to your local environment. #541
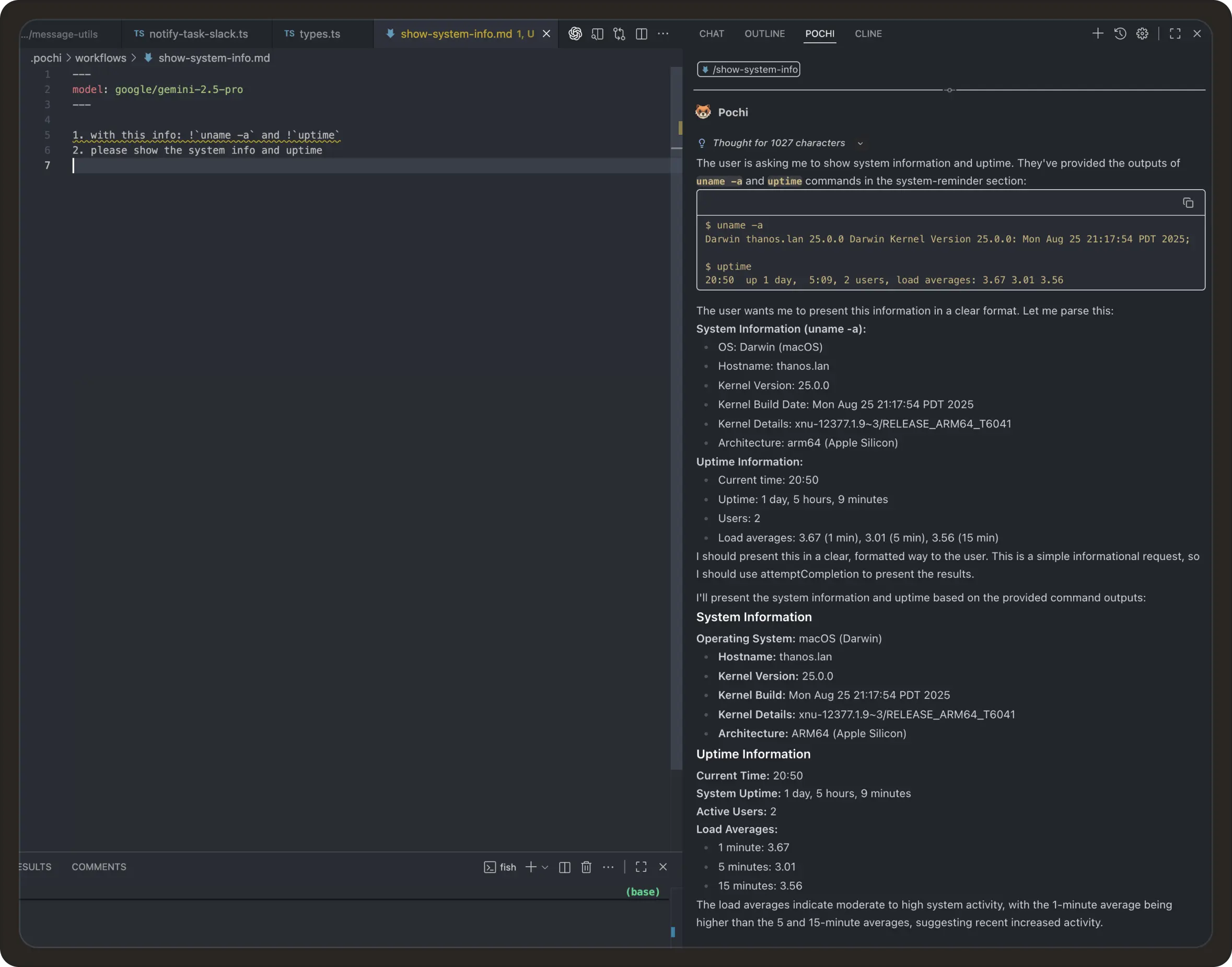
✨ Enhancements
-
Faster Markdown Rendering with
streamdown.ai: We’ve replacedreact-markdownwithstreamdown.aiin the VS Code web UI. This upgrade improves performance, adds streaming-based markdown rendering, and ensures better support for rich content (like math, code blocks, and workflows). #401 -
Extended Multimedia Support in
readFileTool: ThereadFiletool now supports reading multimedia files, including images, audio, and video, for multimodal models. Pochi automatically detects file types and encodes the content inbase64for models that can interpret visual and auditory data. #539, #569
- Added Linux ARM64 Release: Pochi is now available for Linux ARM64 systems, improving compatibility for developers running on Raspberry Pi or ARM-based environments. #543
Weekly Update #7
Oct 14, 2025
TL;DR
This week, we focused on making Pochi more capable for builders who live in the terminal. We extended image-prompt support to the CLI, added global workflows for shared automations, and made the command-line experience smoother with shell autocompletion.
We’ve also shipped .pochiignore support and small but delightful touches like copying images directly from the extension chat.
🚀 Features
- CLI Autocompletion: The Pochi CLI now supports shell autocompletion for
bash,zsh, andfish. Improve your flow as you discover commands, subcommands and options while typing, without the need to stop and check docs mid-flow. #307
-
Global Workflows: You can now store workflows globally in
~/.pochi/workflows, and Pochi will load them across all workspaces. Easily share automations, setups, or linting rules, while allowing your team to maintain consistent review or deployment routines.#123, #517 -
Image Prompts in CLI: You can pass images directly to Pochi from the CLI, be it a diagram, a UI screenshot, or a flow chart. Models interpret and respond to your visuals, explaining issues, parsing charts and generating code based on UI mockups. #513
✨ Enhancements
.pochiignoreSupport: You can now use.pochiignore(just like.gitignore) to exclude files and directories from Pochi’s context, keeping your large repositories lean and your prompts focused on the task at hand. #515 , #516
# Example .pochiignore
node_modules/
dist/
*.log- Copy Images from MCP and Attachments: You can now right-click any image generated by MCP tools or shared in chat to copy it to your clipboard or open it in an editor tab. A small addition, but a big win for anyone working with visual data or model-generated diagrams. #500
🐛 Bug fixes
- Command Queue Stability: Fixed race conditions between queued and other requests (particularly during preview operations) to improve execution consistency and error handling. #528
Weekly Update #6
Oct 03, 2025
TL;DR
Q4 is here, and Pochi’s cooking. 🍳
We’ve rolled out new built-in tools (webFetch and webSearch) that extend Pochi’s server-side capabilities, added support for new AI vendors (Codex and Qwen Coder), and released a new tutorial that shows how Pochi can act as your AI teammate in GitHub Actions.
Let’s start! 🧡
🚀 Features
- Built-in Tools: Pochi now supports server-side tools, allowing it to register and expose capabilities that come bundled directly with the app. The first two built-in tools introduced are
webFetchandwebSearch. These let AI agents fetch, read, and process web content directly. #447
-
New AI Vendor Support: Pochi now supports Qwen Coder and Codex, adding new model vendors alongside Claude, Gemini, and Copilot. We've also introduced native compatibility with Anthropic’s API format, enabling faster and more stable integration with Claude models. #52, #304, #302
✨ Enhancements
- Model-Aware Workflows: You can now define which model a workflow should use directly in its configuration. This gives you more control over which LLM handles each automation, especially useful if your team switches between providers like Claude, Gemini, or Codex. #343
🐛 Bug fixes
-
Assistant Retry Logic: Fixed an issue where assistant messages without tool calls were treated as new steps instead of retries, causing the retry count logic to behave incorrectly. #342
-
Diff View in VS Code: Files open before a diff operation are now reopened after accepting or rejecting changes, preserving your workspace layout. #440
📖 Resources
- We’ve published a new tutorial: Build Your Own AI Teammate with Pochi in GitHub Actions. Learn how Pochi can review and gatekeep PRs, enforce coding standards, open issues, and even run as a continuous background agent.
Weekly Update #5
Sep 26, 2025
TL;DR
This release introduces a manual sub-task execution mode for more control over sensitive workflows. We’ve also added MCP support in the CLI, enabled GitHub Copilot and Claude Pro/Max authentication, and shipped new tutorials and key security and stability improvements. 🙌
🚀 Features
- Manual Execution Mode for Sub-Tasks: Sub-tasks created with
newTaskcan now be run in a manual, step-by-step mode avoiding large unmoderated changes to your codebases in your sensitive workflows. #300
- MCP support in CLI: The CLI now supports running your Model Context Protocol (MCP) servers, allowing you to connect your tools, and run MCP-powered workflows directly from the terminal. This update brings the CLI closer to parity with the VS Code extension. #100
-
AI Tooling Integrations (GitHub Copilot + Claude): You can now authenticate and use your GitHub Copilot and existing Claude Pro/Max subscriptions within Pochi across both the CLI and VS Code. Once authenticated, these services provide completions and suggestions directly in your workflows, enhancing the overall AI-assisted development experience. #184 , #61, #306
-
Improved VS Code Configuration Navigation: VS Code commands like
Pochi: Open MCP Server Settingsnow open the relevant config file and jump directly to the specific setting, #301
✨ Enhancements
-
Enhanced Gemini Model Support: We've improved existing image input capabilities with added PDF and video inputs, providing richer multimodal workflows with Gemini models. #219
-
Malformed Custom Agents in VSCode Settings: Previously ignored malformed agent files (e.g., with YAML parsing errors) are now displayed in the settings UI with a clear warning, making it easier to debug and fix broken custom agent configurations. #391, #415
📖 Resources
Weekly Update #4
Sep 19, 2025
TL;DR
We are excited to introduce Queued Messages — type prompts in advance and stop waiting for Pochi to finish a task! We also launched a new Tutorials section with guides on voice-driven development and Mermaid graphs. Have tips or insights? Contribute your own via PRs! Plus, Pochi now supports more file types, and the CLI is friendlier and more interactive. ✨
Features 🚀
-
Queued Messages: Don't wait around —
⌘/Ctrl + ↵to line up your next prompt when Pochi is busy. #286
-
Tutorials: A new documentation hub to help you get more out of Pochi. This week: voice-driven dev with Hex, and Mermaid graph communication.
Enhancements ✨
-
Multimedia file support: Share not just images, but also PDFs and videos with Pochi. #271
-
Claude Code login: The CLI now supports authentication with Claude Code. #282
-
Friendlier CLI experience: Interactively pick auth vendors and navigate through tasks, get clearer help/error messages, and see upgrade notices on startup. #287, #294, #308, #329, #357
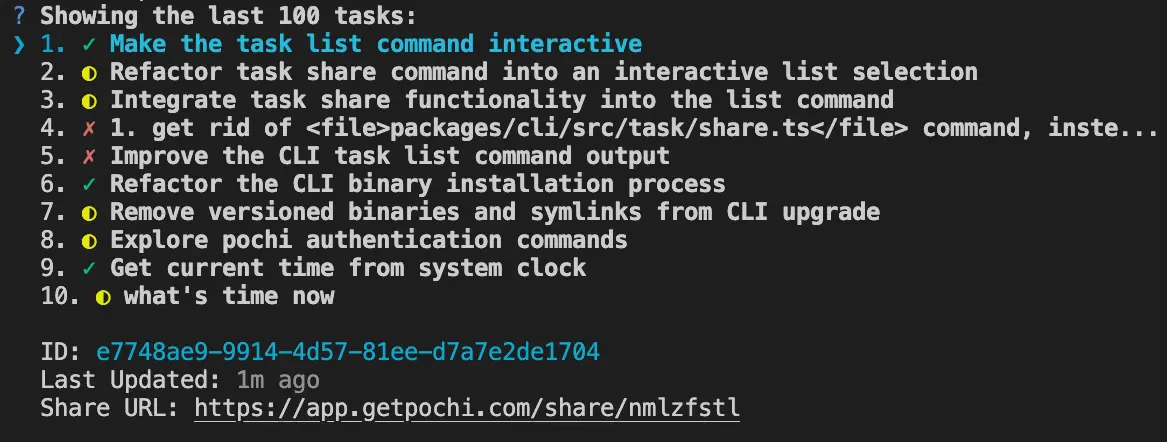
-
Docs updates: Added documentation for queued messages and tab completion model settings and improved VS Code docs. #317, #321, #365
Bug fixes 🐛
- VS Code UX tweaks: Unified drag-and-drop overlays with the prompt editor, fixed tooltip arrows, and ensured model selections are preserved with clear alerts when a model is unavailable. #350, #316, #373
New Contributors 🐾
A belated shout-out to @DESU-CLUB for their first contribution last week — and another one this week! 🥳
Weekly Update #3
Sep 12, 2025
TL;DR
This week we brought custom agents to life!🐣 Pochi CLI is on npm, newTask makes it simple to create and manage tasks right from the terminal, and Mermaid diagrams render beautifully inside the app. MCP interactions are smarter too, and the docs and UI keep getting smoother with every update. ✨
Features 🚀
- Custom Agents: Define your own assistants in
.pochi/agentsusing markdown. #176, #181 newTaskin CLI: Spin up tasks directly from the terminal, each with its dedicated agent. #232- Mermaid diagrams: Drop Mermaid code blocks into Pochi and see them rendered as nice diagrams. #255
Enhancements ✨
- Pochi CLI on npm 📦:
npm install -g pochiand get it running! #238 - Custom models for completion: Use your own models for code completion in VS Code. #251
- MCP instructions: MCP servers can now guide models on tool usage, enabling more complex interactions. #254
- Token auth: Log in with a token when browser auth doesn't work. #235, #236
- Diff view focus mode: Pochi automatically closes a file's regular editor tab when opening its diff view. #197
- More CLI commands:
pochi mcp listto inspect configured MCP servers, andpochi task listto check task lists. #231, #266
- VS Code UI polish: Autocomplete mention list is responsive and tabbable, workflow list is collapsible and better spaced. #215, #204, #230, #228, #242
- Docs updates: Added checkpoint feature and updated GitHub integration docs with API key setup. #203, #262
Bug fixes 🐛
- Scoped replies: Pochi only responds when you start a comment with
/pochi. #202
Weekly Update #2
Sep 5, 2025
TL;DR
We had a massive week — 62 PRs shipped 🎉!
Pochi can now reply to you right in GitHub comments & issues, the interface speaks more languages with new i18n support, and we rolled out a sleeker, more powerful background job system. On top of that, the CLI got smarter, autocomplete got friendlier, and the docs got a glow-up!
Features 🚀
- GitHub Action integration: Pochi now lives in your PR comments / issues! Ask for help in a PR with
/pochi. #76 - Internationalization (i18n): The VS Code extension now supports 🇺🇸 🇨🇳 🇯🇵 🇰🇷. Want your language included? Open a PR! #90
Enhancements ✨
- CLI upgrades: The Pochi CLI got a big boost this week!
- Enhanced Background jobs: Added terminal integration and lifecycle controls. Enhanced the job UI with collapsible detail logs and readable IDs for a clearer experience. #81, #97
- Autocomplete: Pochi suggests relevant tools, functions, and variables to help you type prompts faster. #89
- Documentation updates: Refreshed CLI usage docs, expanded model provider configuration examples, and added Slack integration documentation. #133, #141, #82
Bug Fixes 🐛
- File writing reliability: The CLI ensures directories exist before writing, so
writeToFiletool won't fail. #118 - Code completion fix: Corrected how VS Code calculates the replacement range for suggestions, so completions insert correctly. #131
New Contributors 🐾
@karim-coder made their first contribution this week! Welcome aboard! 🎉
Weekly Update #1
Aug 29, 2025
TL;DR
This week we polished the VS Code extension with some UX upgrades, open-sourced the Pochi CLI, and did a few rounds of codebase cleanup to make contributing easier and friendlier for newcomers. We look forward to your first visit to the repo!
Enhancements ✨
- Drag & drop images: Share visuals with Pochi in the VS Code chat just by dragging them in. #64
- Improved docs: Updated structure and added guidance on model settings for easier use. #60, #63 , 900d162
- Model pricing at your fingertips: Check model costs directly in settings before choosing one. #74
Bug Fixes 🐛
- File search now correctly surfaces matching files: Queries that used to return empty results will now behave as expected. #79